知识图谱构建流程
知识图谱(Knowledge Graph)源于语义网、图数据库等相关学术研究领域,不同领域对知识图谱研究的侧重有所不同,如自然语言处理、知识工程、机器学习、数据库和数据管理等领域都有不同的研究与应用。

自然语言处理领域:“信息抽取”是其核心,如何从非结构文本数据中抽取知识图谱所需要的三元组数据是一项极富挑战性的工作。 “语义解析”也是一个热点,如何将用户输入的自然语言问题转化面向知识图谱的结构化查询,就需要语义解析,这也是智能问答中的重要环节。
知识工程领域:百科知识的“大规模本体和知识库构建”是一个主题,如基于百科知识构建大规模知识图谱数据集DBpeida和Yago。近年来,面向特定领域的知识图谱构建也在行业应用中得到推广,如医疗知识图谱、制造业知识图谱、电商图谱等。
此外,知识图谱上的推理理论基础与应用也是一个前沿研究方向。
知识图谱构建的学习技术

知识图谱构建首先需要确定可用数据源,如结构化数据、机器可读的开放本体或辞典、开放链接数据和开放知识库、行业知识库和行业垂直网站、在线百科(维基、互动、百度)和文本等数据。然后,有效地采集数据,如开放链接数据采集、百科采集、文本信息采集(网络爬虫与主题爬虫)等。

知识表示层次
逻辑层:RDF,WIDETABLE,Property Graph 逻辑存储方案,互相映射;
存储层:JSON-LD,N-TRIPLE,EXCEL/CSV 序列化文件交换格式;
计算层:显式(实体关系网络)与隐式(分布式表征)的知识关联与推理。
要了解知识图谱的几种常见知识表示方法,选取合适的数据表示形式,确定知识图谱核心数据结构。如,数据——实体、本体、陈述;元数据——版本管理、信息溯源。
在知识图谱构建过程,知识抽取、知识融合和知识计算是关键的工作。特别是针对文本数据,需要结合NLP技术从文本中抽取知识,也可以基于知识反向标注文本;利用RDF图模型,融合不同领域、不同结构、不同格式的知识;领域知识与业务计算相组合,在知识图谱上进行推理、机器学习、网络分析等知识计算。
实体抽取:也称为命名实体识别(Named Entity Recognition,NER),是指从文本数据集中自动识别命名实体(包括:人名、地名、机构名、专有名词)。
基本方法包括:
1.基于规则和词典方法——构造规则模板(特征:统计信息、标点符号、位置词等);
2.基于机器学习方法——K-最近邻算法、HMM模型、CRF模型、BI-LSTM-CRF;
3.有监督学习与先验知识相结合方法——词典辅助下的最大熵算法、远程监督学习。
例:医疗知识图谱知识库的症状自动识别

同义关系抽取,是指从文本数据集中自动识别那些代表同一概念、实体或属性的术语对,即把描述同一概念或实体的指代抽取出来。
基本方法包括:
1.词典方法——WordNet、哈工大同义词词林扩展版;
2.基于词法模式方法——手工编写模式、规则模式自学习方法;
3.浅层语义分析方法——采用“词汇-文档”矩阵描述词汇与文档关系。
实体属性抽取,是指从文本数据集中自动识别实体、属性、属性值三者组成的信息对关系。
基本方法有:
1.基于规则模板方法——针对特定领域制定领域抽取模板、规则学习;
2.基于机器学习方法——为不同属性训练不同的模型:时间模型、货币模型、组织机构、CRF、LSTM;
3.基于远程监督学习方法——使用现有知识自动生成语料、Bootstrapping
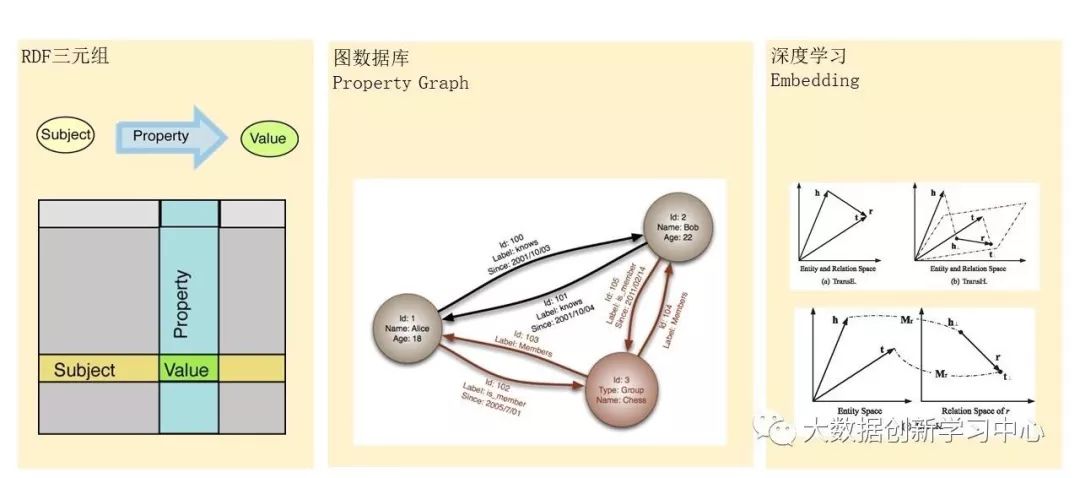
例:中标数据抽取
(1)抽取中使用机器学习算法SVM和规则模型相结合的多分类模型,对中标数据进行业务需求划分;
(2)表格型抽取包括:表格定位、表头识别、表格数据抽取、表格属性数据对齐等;
(3)文本型抽取包括:正文抽取模型、命名实体识别模型、CRF序列模型抽取功能、句式模板自学习功能等;
(4)列表项抽取包括:列表划分、属性值对齐等。

关系抽取,文本语料经过实体抽取,得到一系列离散的命名实体。为得到语义信息,需要从相关语料中提取出实体之间的关联关系。
基本方法包括:
1.监督学习方法——需要大量语料进行模型训练、基于统计学方法(基于多特征的分类问题、关系分类)、基于神经网络、深度学习的方法;
2.半监督学习方法——基于Bootstrap的方法;
3.非监督学习——基于聚类的方法、远程监督学习。
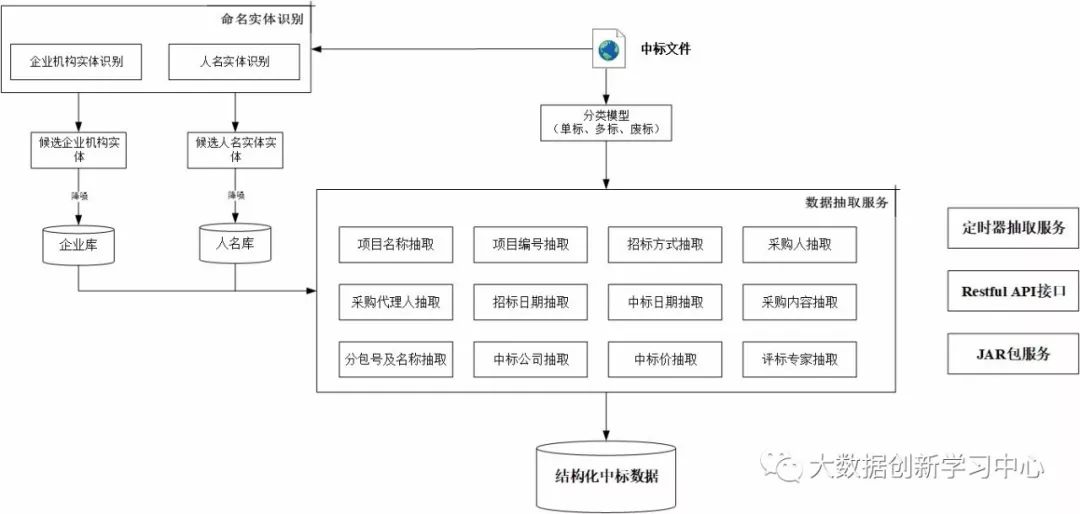
例:多策略学习算法的竞争关系抽取
•句子收集 •Pattern学习 •Pattern打分 •竞争关系抽取
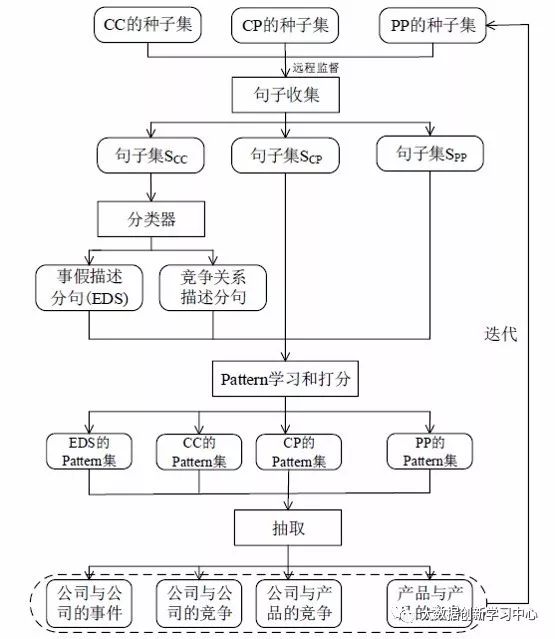
实体链接,是指将数字资源或其片段与其知识本体相关联,指出资源在语义层面上的特征。其主要目的就是赋予各种类型的数字资源以本体语义,辅助搜索。
基本方法:
1.基于规则标注方法——预定义文档集合规则;
2.基于概率标注方法——基于文本分类、基于统计分析文本中的词与词、句与句上下文关系的模型方法、基于统计主题文档分类器模型的方法;
3.基于语义相似度标注方法——语义相似度模型。
![]()
北京大学邹磊教授开源了RDF知识图谱数据的存储和查询系统——gStore。
gStore系统可支持SPARQL 1.1标准,提供了集中式和分布式两种部署方式,在十亿规模的Benchmark数据集测试上,平均性能优于Virtuoso和Apache Jena等国外同类产品。
gStore系统架构

在导入RDF知识图谱数据和构建索引阶段,将用户输入RDF三元组文件表示成一张图G,通过链接列表方式直接存储图G本身。为加快子图匹配查询速度,通过编码方法,将RDF图G的每个实体节点和它邻居属性以及属性值编码成一个Bitstring节点,得到一张标签图G*。
gStore系统给出一种建立在面向G*图的VS-tree索引结构,有效地支持在线查询阶段的搜索空间过滤,将用户SPARQL查询转换为子图匹配查询。
知识图谱(KG)是人工智能时代实现概念识别、实体发现、属性预测、协同推理、知识演化和关系挖掘等功能的底层关键技术,也是大知识与数据融合、数据认知与推理的核心技术。
知识图谱构建过程是一个人机结合的不断迭代过程,以机器自动学习为主、专家定义与修正结合。需要人工介入的工作包括Schema定义、部分结构化知识准备、机器学习结果校验,依据用户的反馈、语料的增加与更新,不断进行模型的更新与迭代。