学术交流
Learning to Ask Conversational Questions by Optimizing Levenshtein Distance
作者:刘中坤,任鹏杰,陈竹敏,任昭春,Maarten de Rijke,周明 来源:The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021) 链接:
- 论文:
- 代码:
- 数据集:
- 数据集构建UI:
撰写:刘中坤 校稿:任鹏杰
背景及动机
明析问题生成(Asking Clarification Questions)是对话式信息获取的重要部分,是其混合驱动特性的主要体现,因此有很重要的研究意义。
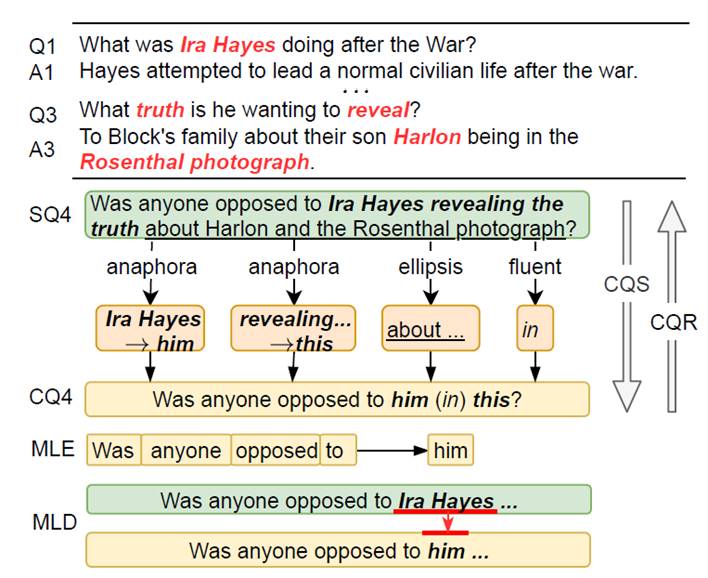
图1. 对话式问题改写
传统的明析式问题可分为两类,生成式问题生成(Conversational Question Generation)与检索式问题生成(Conversational Question Ranking)。生成式问题生成基于对话历史直接生成相应问题,但生成的问题很难保证相关。检索式问题生成通过检索大规模数据库返回最可能的明析问题,一般来说,能够保证相关。但是,检索式问题生成得到的问题往往是完整的,冗长的问题,并没有对话中常见的省略和指代,这在对话中显得非常不自然。如图1,通过检索到的问题SQ4,非常冗长,且描述的非常完整,不适合出现在对话中。
本文提出Conversational Question Simplification (CQS), 通过模拟对话的特性,例如指代和省略,将检索到的完整的问题转化为对话式问题。如图1,通过四个模拟过程,将SQ4转换为CQ4。现有的方法都是基于最大似然估计Maximum Likelihood Estimation (MLE) 的,逐步生成每一个单词,为每个单词赋予同样的关注,满足于容易学到的单词,比如在SQ4中的单词,而容易忽略对话式单词,比如him等,本文认为这才是最重要的。
为了解决上述问题,本文提出一种新的范式,最小化莱文斯坦距离Minimum Levenshtein Distance (MLD),即最小化编辑次数,来着重优化莱文斯坦距离相关的单词,例如Ira Hay和him。由于MLD 是离散的,本文提出一种Reinforcement Iterative Sequence Editing (RISE) 框架去优化MLD。
RISE 通过迭代改写输入来减少与目标输出的莱文斯坦距离。改写包括保留单词Keep (K), 删除单词Delete (D), 插入词组Insert (I), 替换词组Substitute (S)四种操作实现,但训练数据并不包含这些标签。同时,传统的标签采样方式例如ϵ-Greedy Sampling 都是逐个单词独立采样,没有考虑单词间改写操作的依赖性。因此,本文提出一种基于动态规划的采样方式 Dynamic Programming based Sampling (DPS)来跟踪并建模单词间的改写依赖。在CANARD和CAsT两个benchmark数据集上,实验证明RISE能够超过SOTA方法并且能够迁移到未知的新数据上。
方法
为了迭代优化莱文斯坦距离,本文首先给出一种层次强化学习的建模方式。之后介绍其组成模块,训练方式。
层次强化学习建模
本文将整个优化过程建模为两个马尔可夫决策过程:1)编辑层 (editing),为全部单词预测改写标签 2)实现层 (phrasing),为插入和替换改写标签预测一个词组。
编辑层首先被建模为马尔可夫过程五元组形式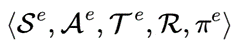 :状态,动作,转移函数,奖励,策略网络。当前轮状态为
:状态,动作,转移函数,奖励,策略网络。当前轮状态为 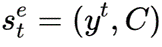 ,即上一次迭代修改的输出以及对话上下文;动作为全部单词的编辑操作。实现层也是五元组形式
,即上一次迭代修改的输出以及对话上下文;动作为全部单词的编辑操作。实现层也是五元组形式 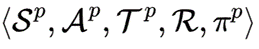 ,状态为
,状态为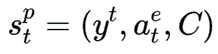 ,还包括了编辑层的动作;动作为改写的词组。转移函数都是输入当前状态返回下一个状态,共享一个奖励函数,并包括两个策略网络:编辑策略网络,实现策略网络。
目标是最大化期望奖励:
,还包括了编辑层的动作;动作为改写的词组。转移函数都是输入当前状态返回下一个状态,共享一个奖励函数,并包括两个策略网络:编辑策略网络,实现策略网络。
目标是最大化期望奖励:
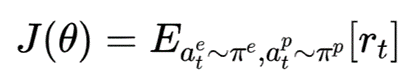
通过策略梯度进行优化:
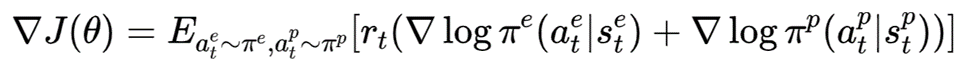
策略网络
策略网络包含两部分,编辑策略网络,实现策略网络。如图2:
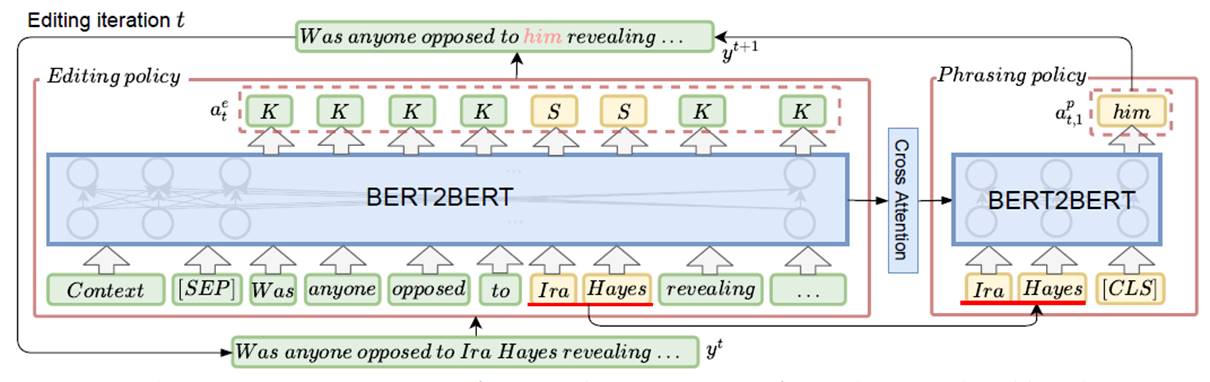
图2. 模型概览.
左侧为编辑策略网络,输入上下文以及上一轮迭代的输出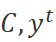 ,输出全部单词的改写标签
,输出全部单词的改写标签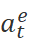 。首先将输入展开为逐个单词,输入到BERT2BERT的encoder层,将每个单词的表示,通过全连接层,预测 :
。首先将输入展开为逐个单词,输入到BERT2BERT的encoder层,将每个单词的表示,通过全连接层,预测 :
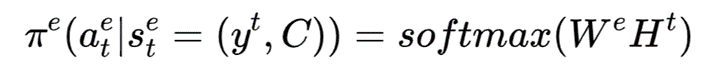
右侧为实现策略网络,输入CLS和(对于插入标签)插入标签前后的单词或(对于替换标签)被替换的词,如Ira Hayes,预测被插入或被替换的单词,如him。本文将全部插入或替换标签得到的CLS的表示通过全连接层,预测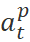 :
:

奖励
本文给出的奖励函数如下:
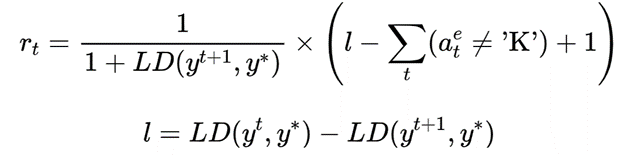
这里 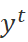 ,
,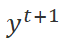 ,
, 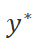 ,
,  分别表示当前轮输入与输出,最终目标输出,莱文斯坦距离函数。一方面本文对得到更低的莱文斯坦距离的编辑标签奖励,另一方面对于额外的非保留 (K)操作进行惩罚,这促使模型能使用准确的编辑操作降低莱文斯坦距离。
分别表示当前轮输入与输出,最终目标输出,莱文斯坦距离函数。一方面本文对得到更低的莱文斯坦距离的编辑标签奖励,另一方面对于额外的非保留 (K)操作进行惩罚,这促使模型能使用准确的编辑操作降低莱文斯坦距离。
训练
由于没有对应的编辑操作标签进行训练,本文提出了一种动态规划的采样方式进行采样。采样过程如下

图3. 动态规划的采样示例.
如图3,左上角为模型输出的每个标签的采样概率,中间红色为计算动态规划矩阵,蓝色为根据矩阵结果进行采样。
第一步,构建动态规划矩阵。给定当前轮输入与最终目标输出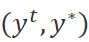 , 本文第一步首先构建了一个矩阵
, 本文第一步首先构建了一个矩阵 (包含[SEP]),每一步保存前i个编辑标签
(包含[SEP]),每一步保存前i个编辑标签 将
将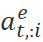 转化为
转化为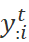 的期望,这样
的期望,这样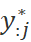 保存的就是整个编辑标签将
保存的就是整个编辑标签将 转化为
转化为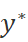 的期望了。其计算方式如下:
的期望了。其计算方式如下:
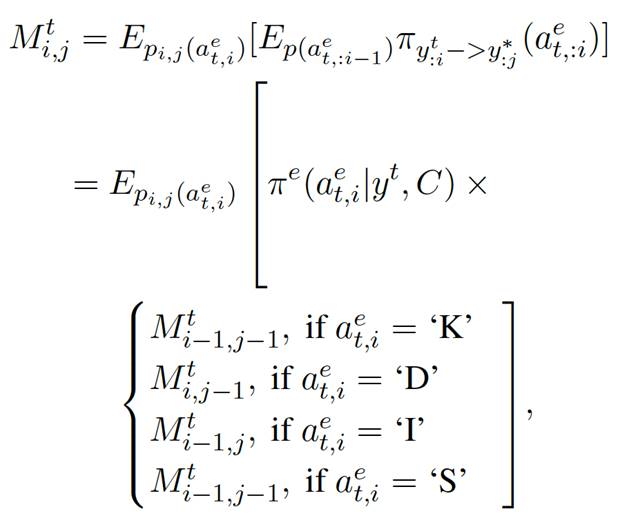
其中,标签的期望被分解为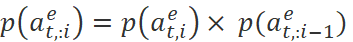 ,转化概率
,转化概率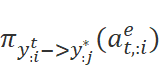 根据第i个单词的标签的不同被分解为不同的组合。例如,第i个单词为保留,那么我们需要的前个单词转化为的前
根据第i个单词的标签的不同被分解为不同的组合。例如,第i个单词为保留,那么我们需要的前个单词转化为的前 个单词,因此需要乘以
个单词,因此需要乘以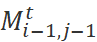 。这样,原问题就可以一步一步分解为子问题,并通过矩阵保存子问题结果,最终进行求解了。
。这样,原问题就可以一步一步分解为子问题,并通过矩阵保存子问题结果,最终进行求解了。
 为本文采样的概率。不同于ϵ-greedy基于模型单个单词标签的输出
为本文采样的概率。不同于ϵ-greedy基于模型单个单词标签的输出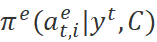 进行采样,可以建模单词标签采样间的联系,考虑单词已采样的标签,其定义如下:
进行采样,可以建模单词标签采样间的联系,考虑单词已采样的标签,其定义如下:

这样,模型基于 就能考虑之前的采样结果了。需要注意的是,只有当  时才允许保留和插入,反之才允许替换和删除
时才允许保留和插入,反之才允许替换和删除
第二步,基于动态规划结果采样。如图3蓝色框,本文基于 保存的就是整个编辑标签将 转化为 的期望”从矩阵  基于蓝色箭头采样,从右下角到左上角,其转移方式如下:
基于蓝色箭头采样,从右下角到左上角,其转移方式如下:

当遇到保留和替换时,i和j都减少1,当遇到删除时,删除的一个单词,所以j不变i减少1,插入则相反,i不变j减少1。需要注意的是,只有当时才允许保留和插入,反之才允许替换和删除。其采样结果如上图右上角所示,本文将替换与删除操作合并为替换操作(Ira Hayes替换为him),以提供给替换操作更多信息。同时,保留替换与插入标签对应的的一个或多个单词,合并为标签对应的词组。当推断时,RISE会迭代修改输入,直到输入不再改变或达到最大迭代次数(3次)。
Experiments
实验方面,本文采用两个benchmark当数据机CANARD和CAsT进行测试。由于CAsT样本较少,只有479个,本文将在CANARD数据集上训练当模型,直接应用到CAsT上进行测试,来检测模型的迁移能力。

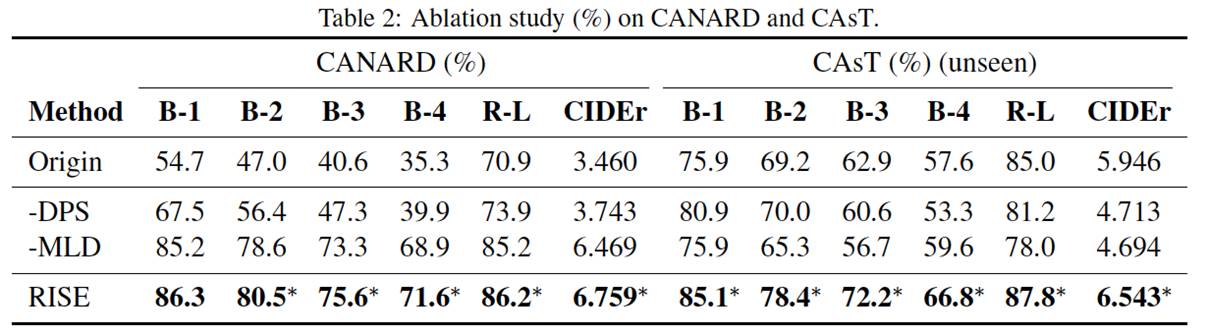
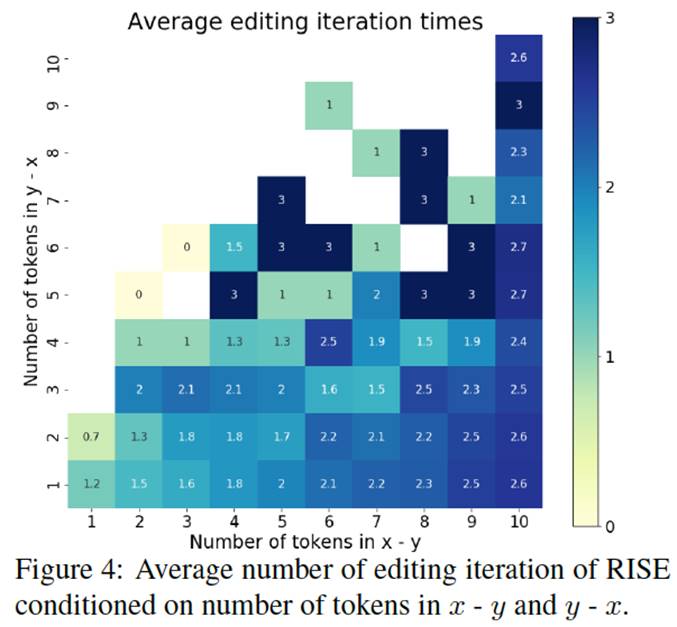
可以看出,RISE无论是在同分布数据集还是在未知分布数据集,表现都很优异,同时,本文提出的MLD与DPS都能够显著提高模型最终的结果。
本文还对模型迭代次数进行分析,进一步验证了模型模拟省略和指代等对话特性的能力。