学术交流
Few-Shot Variational Reasoning for Medical Dialogue Generation
作者:李冬冬,任昭春,任鹏杰,陈竹敏,范淼,马军,Maarten de Rijke 来源:The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2021 链接:
- 论文:
- 代码:
- 数据集:
- 数据集构建UI:
撰写:李冬冬 校稿:王闪闪
1.简介
会话范式越来越多地用于将人们与信息联系起来,既可以满足开放领域的信息需求,也可以用于高度专业化垂直领域,本文聚焦于医疗对话领域,提升在标注数据量少的情况下对话生成效果。医学对话的生成旨在提供自动而准确的回复,以帮助医生以有效的方式获得诊断和治疗建议。在临床治疗期间,会话式医疗系统可以充当医师的助手,以帮助响应患者的需求,即询问症状,做出诊断并开出药物或治疗方法。
当前的医疗对话系统依旧面临着一系列的挑战:在医学对话中,注释者需要医学专业知识来注释数据,这意味着标注成本极高,出于隐私原因,大规模人工标注无法满足;当前多轮对话系统还极少考虑从大规模外部数据中提升模型的语义理解能力;为了帮助病人和医生理解医疗对话系统为什么生成特定的回复,可解释性不可或缺,当前只有少数的任务导向对话的方法在无标注数据的情况下考虑使用显式的对话状态追踪。

图 1. 感染科医疗对话样例
为了解决上述挑战,本文为医疗对话生成任务提出了一种变分推理模型 VRBot。其包含了病人状态追踪器(Patient State Tracker)和医师策略网络(Physician Policy Network)分别用于追踪病人生理状态(state)和检测医生动作(action)。不同于使用大量标注信息的方法,VRBot 将 state 和 action 都视为先验为Categorical Distribution的隐变量(latent variable),并且采用一个随机梯度变分贝叶斯(SGVB) estimator来逼近隐变量的真实后验。对于没有中间标注的数据,VRBot依旧能够追踪病人生理状态以及通过预测治疗方法的方式来生成内容丰富和准确的回复。
2.问题定义
医疗对话系统:对于一个包含T个对话轮的医疗对话d = {U1,R1,U2,R2,...,TT,RT},其中Ut 和Rt分别表示了病人的问题和医师回复。在第t个对话轮,给定Rt-1和Ut,外部知识图谱Gglobal,对话系统目标为生成回复Rt。假设VRBot这个模型的参数为θ,其目标为最大化以下概率:
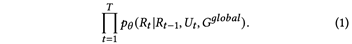
病人状态与医师行为:基于text-span的对话状态追踪器兼具了简单和可解释两个方面的优势。本文在第t轮定义了一个text-span St 表示病人状态;类似于 St ,另外定义了一个text-span At 表示医师动作,其总结了医师的策略如诊断,药品以及诊疗。医疗对话生成可以分解为三个连续的过程: (1) 生成病人状态 text-span St (2) 生成医生动作 text-span At (3) 生成自然语言的回复 Rt 。
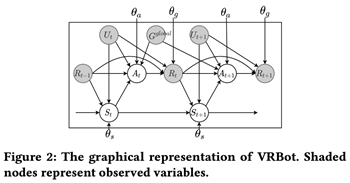
图 2 VRBot的图表示
变分贝叶斯生成模型:大量的病人状态和医师动作这类中间标注往往无法实现,因此,VRBot将St和At均视作隐变量,可以将公式1形式化为:
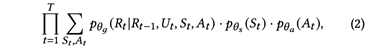
其中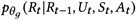 为回复生成器(response generator),而
为回复生成器(response generator),而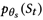 和
和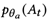 为两个先验网络,分别表示病人状态追踪器(patient state tracker)和医师策略网络(physician policy network)。其图模型表示如图2所示。在第t轮,St从前一轮的状态St-1,回复Rt-1以及问题Ut推导而来,后At通过St ,Rt-1,Ut以及Gglobal推导得到。计算和为:
为两个先验网络,分别表示病人状态追踪器(patient state tracker)和医师策略网络(physician policy network)。其图模型表示如图2所示。在第t轮,St从前一轮的状态St-1,回复Rt-1以及问题Ut推导而来,后At通过St ,Rt-1,Ut以及Gglobal推导得到。计算和为:
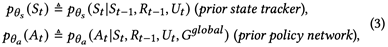
其中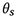 和
和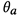 表示模型参数。
表示模型参数。
为了最大化公式2,需计算后验概率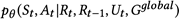 ,然而由于复杂的积分导致精确后验无法求解,为此引入了两个推断网络(inference network)去逼近St和At的真实后验。
,然而由于复杂的积分导致精确后验无法求解,为此引入了两个推断网络(inference network)去逼近St和At的真实后验。
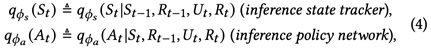
其中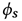 和
和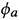 为两个推断网络的模型参数。对于对话的第t轮,推导出生成概率的ELBO用于同时优化先验和推断网络,公式如下:
为两个推断网络的模型参数。对于对话的第t轮,推导出生成概率的ELBO用于同时优化先验和推断网络,公式如下:

3.模型
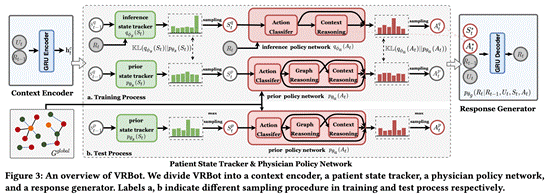
图 3 VRBot结构表示
VRBot主要包含了四个模块,分别为上下文编码器,病人状态追踪器,医师策略网络和回复生成器。建模细节详见论文。
折叠推理与训练:公式5提供了一个联合的训练目标用于优化所有的模块,但是 可能会被从
可能会被从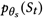 采样到的错误的
采样到的错误的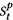 误导。为了解决这个问题,本文提出了一种2-stage collapsed inference训练的方法。第一阶段,让
误导。为了解决这个问题,本文提出了一种2-stage collapsed inference训练的方法。第一阶段,让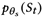 拟合
拟合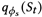 得到训练目标如下:
得到训练目标如下:
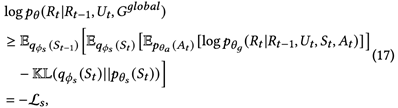
第二阶段,让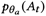 拟合
拟合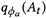 进而得到训练目标如下:
进而得到训练目标如下:
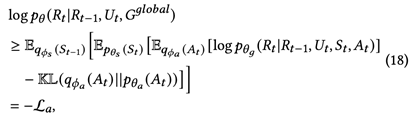
则训练主要包含两个阶段,如下
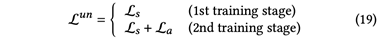
对于存在部分标注state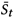 和action
和action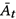 的数据的情况,作者添加额外的loss进行半监督训练,训练目标如下:
的数据的情况,作者添加额外的loss进行半监督训练,训练目标如下:
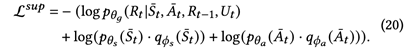
4.实验设置
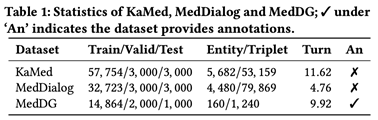
图4 各数据集统计信息
该文实验中采用了三个数据集,分别为KaMed, MedDialog和 MedDG。KaMed是该文从春雨医生采集的,其相比于其他医疗对话数据集包含了更多的对话轮数,并且为其从CMeKG中采集了大规模的外部医疗知识。MedDialog和MedDG为两个基准数据集,MedDG包含了12类肠胃道疾病,并且提供了半自动标注的状态和动作,对话轮数为9.92。MedDialog是从好大夫采集到的,虽然去除了低于3轮的对话,但是其平均对话轮数依旧较低,只有4.76轮。各个数据集的特征统计如图4所示。
5.实验结果
在KaMed和MedDialog两个无标注数据集上的结果如图5所示,其中ma- 和mi- P,R和F1分别表示了macro-averaged 和micro-averaged的Precision, Recall和F1 score,,EA和EG为两个Embedding指标,分别为Embedding Average和Embedding Greedy。图5的结果显示VRBot在多数指标上都达到了最优的结果,但是在ma-P和mi-P上指标低于其他方法,主要原因在于这类方法倾向于生成安全回复,从而其Precision高,但是Recall低。
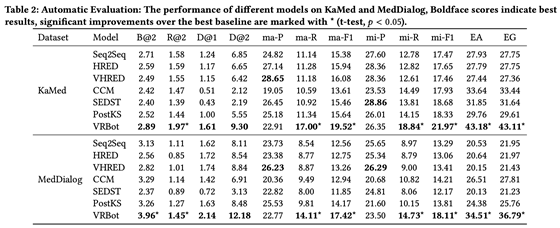
图 5. 各方法在KaMed和MedDialog上的结果对比
在标注数据集MedDG上,我们再作者在多种不同监督比例的情况下对比了更多的baselines,其结果如图6所示。结果显示在半监督和完全监督的情况下,VRBot均取得了最好的结果
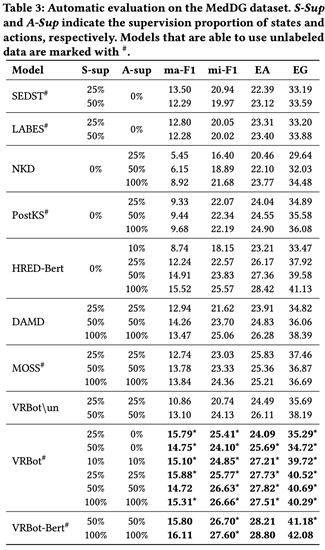
图 6. 各方法在MedDG上的结果对比
作者还做了分析了不同模块对生成效果的影响,消融实验证明了VRBot中的各个模块不可或缺,在KaMed和MedDialog两个数据集上的消融实验证明去除其中任何一个模块都会降低生成对话的质量,结果如图7所示,
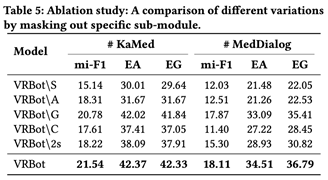
图 7. 消融实验
另外文章中还分析了state text-span和action text-span长度对于实验结果的影响,其中固定|A|=3并且设置|S|为{4,6,8,10,12} 探究state text-span对于结果的影响,固定|S|=10并且设置|A|为 {1,2,3,4,5} 以探究action text-span对于结果的影响,实验结果如图8所示。
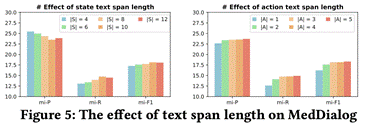
图 8. text-span 长度对于结果的影响
6.总结
本文专注于使用大型未标记语料库的医学对话响应生成,提出了一个名为VRBot的生成模型,该模型使用隐变量对未观测到的患者状态和医师行为进行建模。本文推导了用于优化VRBot的ELBO,并提出了一个2-stage collapsed inference的训练技巧,将ELBO分解为两个学习目标。在三个医学对话数据集上的实验表明,VRBot在无监督和半监督学习中均达到了最优的性能,VRBot-Bert采用Bert为backbone的变体在完全监督的情况下也获得了最好的结果。