学术交流
Conversation Powered by Cross-lingual Knowledge
作者:孙维纬,孟川,孟琪,任昭春,任鹏杰,陈竹敏,Maarten de Rijke 来源:The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2021 链接:
- 论文:
- 代码:
- 数据集:
- 数据集构建UI:
撰写:孙维纬 校稿:孙维纬
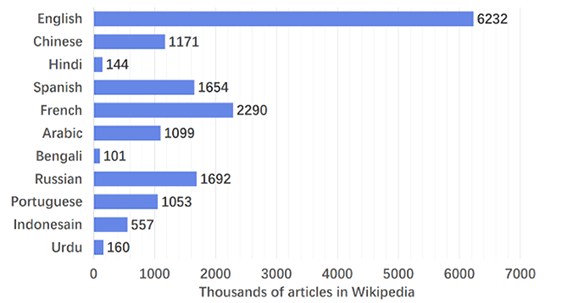
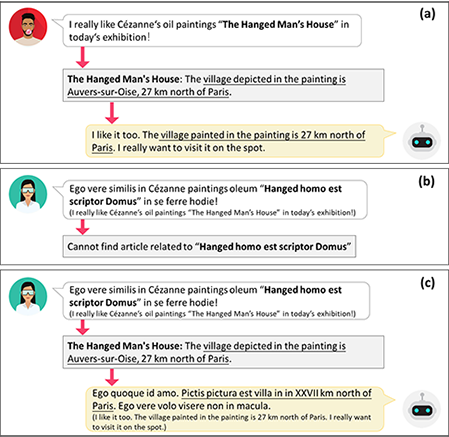
使人可以与机器进行对话,是人工智能研究的重要目标。随着深度学习技术的发展,构建一个智能的闲聊机器人成为可能。为了使一个对话系统生成更富有信息的回复,近年来很多工作在研究如何在对话中使用大规模的本语言的知识库(KGC)。但由于不同语言资源不平衡的问题,已有的方法很难推广到资源匮乏的语言上(如上图左展示,维基百科中英文的文档数量是其他使用人数TOP10语言的文档数量的3到60倍)。为此,我们首次提出了基于跨语言知识的对话(CKGC)任务。如上图右展示,不同于以往使用本语言知识的KGC(图中的a和b),CKGC(图中的c)首先根据对话上下文从外语知识库中检索相关知识,之后再根据外语知识生成回复。CKGC任务面临着两个困难:(1)如何检索以及使用外语的知识;(2)如何评价一个CKGC系统。
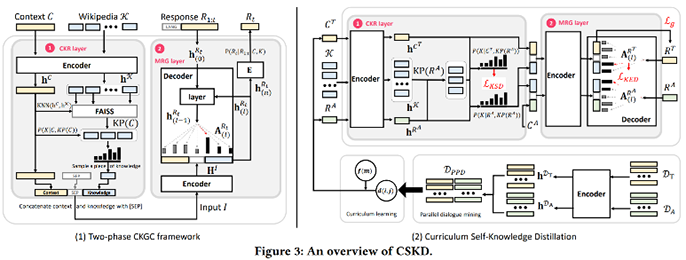

对于(1),我们提出了课程学习的自我知识蒸馏(CSKD)方法,利用大量的非平行的外语对话数据,通过自我知识蒸馏的方法来提升跨语言知识选择以及知识表达的能力。上图左展示了方法的框架,具体来说,我们构建了两阶段框架,分别是1)跨语言知识检索和2)回复生成。我们的模型基于跨语言预训练语言模型mBART。模型首先使用大量辅助语言的对话数据,使用IR系统辅助以及强化学习优化的方法进行预训练。接下来,我们使用包括三个部分的CSKD方法:1)平行对话挖掘,使用预训练模型在对话语料中挖掘话题相同的对话,构建虚拟平行对话数据;2)使用两个training objective,分别对知识选择表示和知识表达表示进行跨语言的自我蒸馏;3)结合课程学习的策略,降低模型自动外挖掘和语言特征所带来的噪声影响。上图右展示了算法流程

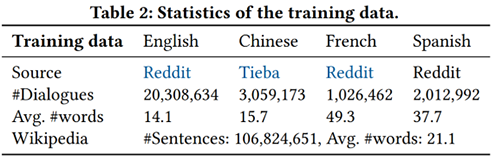
对于(2),作者发布了一个包括三种语言,3,000段多轮对话的CKGC测试数据集,上图左展示了数据统计。我们参考了Wizard of Wikipedia的数据构建方案以及Topic选择,找40位外语专业学生在平台上一对一对话。作为首个多语言的KGC数据,该数据将极大促进相关领域的研究。对于训练数据,我们使用未标注的对话语料,数据统计如上图右展示。
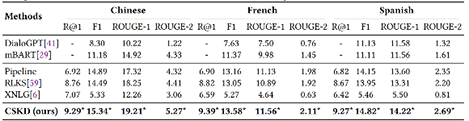
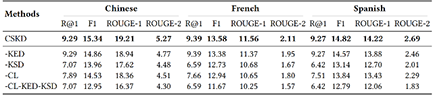
实验方面,如上图左,我们对比baseline包括不使用知识的方法(DialoGPT,mBART),使用翻译的Pipeline,使用一种对话数据进行训练的方法(RLKS,XNLG),使用新标注的数据,在三个语言上验证的方法在知识选择和知识表达中的有效性。同时如上图右的消融实验,我们分析了各个部分的贡献。
总的来说,这篇工作做出了以下的贡献: 1,我们首个提出了基于跨语言知识的对话(CKGC)任务; 2,我们提出了CSKD方案,使用无监督方法学习跨语言知识检索与表示; 3,我们首个提出了CKGC测试集以促进相关研究; 4,我们的实验验证了方法的有效性。