学术交流
Cross-Domain Contract Element Extraction with a Bi-directional Feedback Clause-Element Relation Network
作者:Zihan Wang, Hongye Song, Zhaochun Ren, Pengjie Ren, Zhumin Chen, Xiaozhong Liu, Hongsong Li and Maarten de Rijke 来源:The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2021 链接:
- 论文:
- 代码:
- 数据集:
- 数据集构建UI:
撰写:王梓涵 校稿:王梓涵
1. 背景介绍和动机说明
从合同或其他法律协议文档中提取关键信息是全世界范围个人以及企业需要面临的一项重要任务。每天都有成千上万份与各种交易(如贷款、投资或租赁)相关的合同被起草。这些合同通常包含与法律相关的重要要素,例如终止日期或合同当事人。然而,人工标注和提取合同中的法律要素会消耗大量的人力和时间成本,并且错误率非常高,给律师事务所、公司和政府机构都带来了沉重的负担。在这种背景下,自动合同要素抽取(CEE)应运而生,逐渐引起了相关学者的关注。如下图所示,给定合同中的一个条款,合同要素抽取的任务目标是找到法律上相关的要素(如“within 5 days …… fact”)。合同要素抽取任务可以促进下游应用,诸如相关条款检索,风险评估等。

现有的合同要素抽取方法将该问题看成序列标注任务,即将句子中的每个词分类成一种合同要素。对于序列标注任务来说,一项重要的挑战是如何将知识从一个领域迁移到另外一个领域。如上图所示,相比于个人合同(上方),商业合同(下方)往往用词更为正式,对要素的描述更加复杂和精确。商业合同和个人合同相比,合同文本和要素种类都存在较大的差异,因此将知识从商业合同领域迁移到个人合同领域(或者相反方向)存在着一定挑战。本文定义了跨域合同要素抽取任务,并提出了双向反馈的条款-要素关系网络(Bi-FLEET),完成合同要素抽取的跨域迁移。
值得注意的是,跨域合同要素抽取与跨域命名实体识别任务有很多相似的地方,但是现有的跨域命名实体识别方法并不能直接用于跨域合同要素抽取,面临以下两个挑战:
(1) 需要对更多并且粒度更细的合同要素种类进行迁移:跨域命名实体识别方法往往只用迁移少量几类的命名实体(比如人,组织,地点,日期或者数量)。然而,合同要素的种类更多,粒度也更细。比如,在我们的数据集中,需要迁移超过70类的合同要素。繁多的要素种类会给合同要素抽取的迁移带来巨大的困难。那么,我们就需要发掘不同域中合同要素种类的共有知识。在本文中,我们建模了合同要素种类和条款类型之间的依赖。如下图所示,合同要素和条款之间的依赖往往是不随合同领域发生改变的。

(2) 需要对更长的上下文进行迁移:命名实体识别往往只针对一句话进行实体的抽取,而合同条款往往包含多个句子。也就是说,跨域合同要素抽取需要对更长的上下文知识进行迁移。这意味着,在不同域中,同一种合同要素的上下文组织方式可能变化更多。那么,为了降低上下文组织方式变化的影响,我们在抽取合同要素的同时,识别了合同条款种类,进一步提高跨域合同要素抽取的准确度。
2. 方法简要介绍
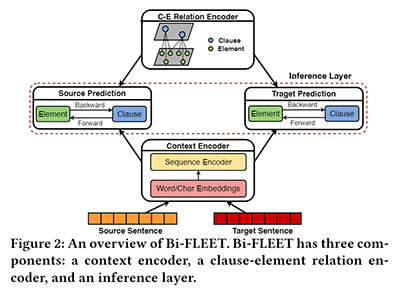
如上图所示,Bi-FLEET网络主要包含三个部分:(1)上下文编码器,(2)条款-要素关系编码器,以及(3)推断层。首先,上下文编码器对合同中的所有句子进行编码;在此基础上,为了建模条款和要素之间的依赖关系,我们构建了跨域的条款-要素关系图,并设计了对应的层次图神经网络;最后,我们利用了多任务框架,同时进行要素抽取和条款识别,并构造双向反馈机制,建模两种任务之间的相互关联。
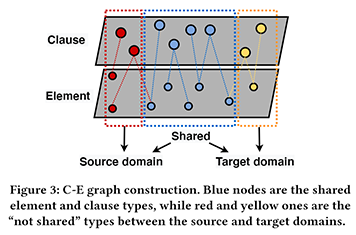
如上图所示,我们构建了跨域条款-要素关系图。其中,红色和黄色节点表示源和目标合同领域特有的条款和要素种类,而蓝色的节点表示两种合同领域所共有的合同要素和条款种类。在此基础上,我们构造了层次图神经网络,编码条款和要素之间的关系,如下所示:
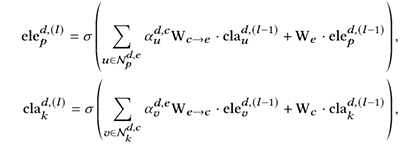
其中,ele和cla分别是要素和条款的表示向量。在此基础上,如下图所示,利用上下文编码器和条款-要素关系编码器得到的表示向量,计算前向反馈向量fw和后向反馈向量bw,进一步修正要素识别和条款分类的结果。
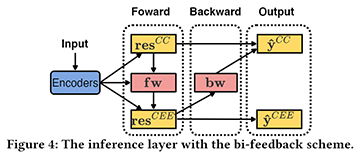
前向反馈信息和后向反馈信息具体计算方法如下所示:
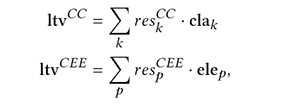
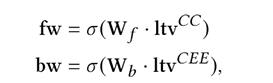
其中,res向量是预测结果的分布向量。最后,我们构建了如下整体损失函数,联合训练合同要素抽取和条款分类任务:
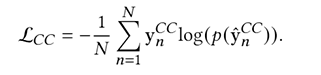
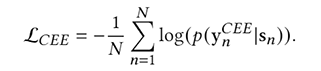
3. 主要实验结果
上表展示了个人合同和商业合同数据集的具体数据。值得注意的是,由于一条合同条款存在多个句子,而合同要素一般只存在于条款中的某一个句子中,因此存在较多的”Neg Sentence”,即不包含要素的句子。
如下图所示,我们首先对所提出的多任务框架训练过程进行了观测。可以发现,多任务之间的提升过程不存在相互矛盾的情况,说明条款分类和合同要素识别两种任务能够相互促进。
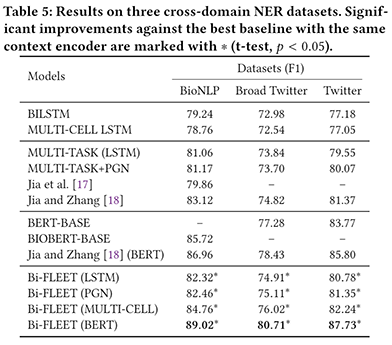
如下表所示,我们在跨域合同要素和跨域命名实体识别数据集上进行了实验。值得注意的是,命名实体识别数据集上不存在条款标签,我们采用了BERT/BIOBERT + Kmeans的方式,无监督地产生标签。我们可以发现,Bi-FLEET在两种数据集上均能取得明显的效果提升,具有非常强的通用性。
4. 更多思考和未来工作
正如前文所说,不同于命名实体识别数据集,合同要素抽取数据集包含有大量的负例句子,这对模型效果有非常大的影响。那么,如何识别这些负例句子是接下来值得研究的课题。除此以外,Bi-FLEET模型仍旧是逐句处理输入数据,如何考虑条款中不同句子之间的关系,建模条款级别的特征,也是我们未来探究的问题之一。