学术交流
山东大学信息检索实验室师生论文获ACL 2024录用
2024年05月23日
近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的6篇论文被ACL 2024录用,其中3篇被主会录用,3篇录用为Findings。ACL2024(The 62st Annual Meeting of the Association for Computational Linguistics)计划于今年8月11日至16日在泰国曼谷召开。ACL是人工智能领域自然语言处理(Natural Language Processing,NLP)方向最权威的国际会议之一,也是CCF A类会议。
录用的文章如下:
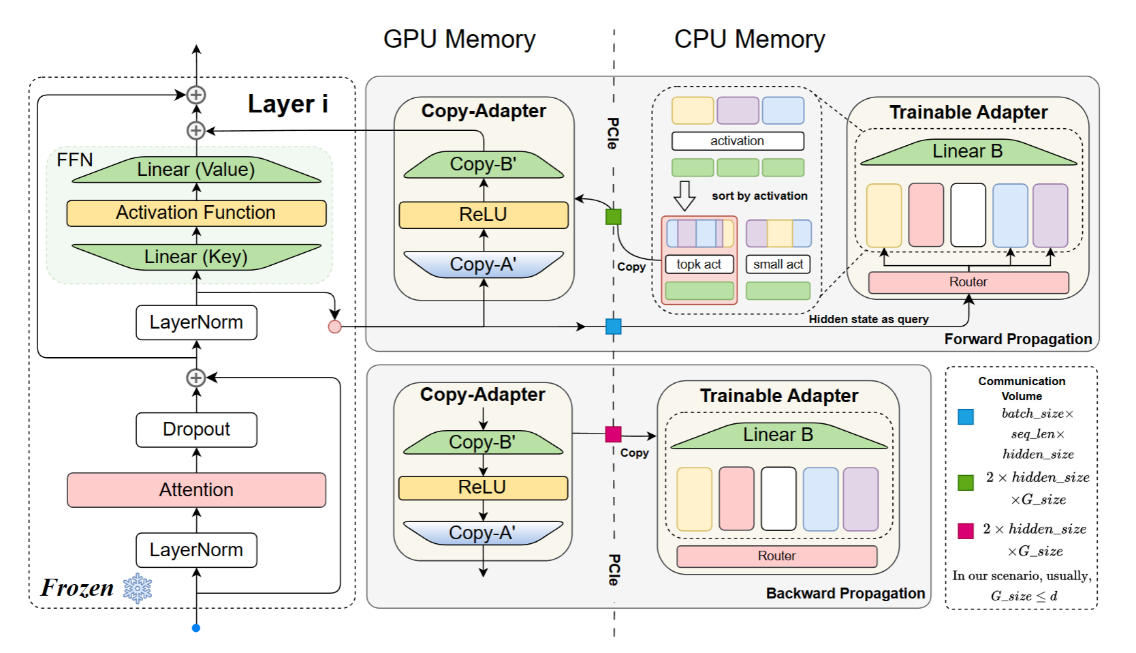
标题:MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter 作者:Jitai Hao,Weiwei Sun,Xin Xin,Qi Meng,Zhumin Chen,Pengjie Ren,Zhaochun Ren 简介:本篇论文探讨了在知识密集型任务上微调大型语言模型(LLMs)时,PEFT方法仍表现出性能不足的问题。PEFT允许在资源受限的情况下对LLMs进行微调。然而,可训练参数的限制导致采用PEFT微调的LLMs在处理复杂、知识密集型任务时性能不佳。通过实验,本文发现,增加可训练参数的数量可以提高部分PEFT方法在知识密集型下游任务上对LLMs的性能。因此,本文提出了一种显存友好型方法,在资源有限的条件下,可以对插入了更大Parallel Adapter的LLMs进行微调。首先,由于Parallel Adapter的结构与前馈神经网络(FFNs)相同,本文利用LLMs中FFNs存在的激活稀疏性,将Parallel Adapter中的两个矩阵视为按神经元划分的键值对(key-value pair),使用较大的CPU内存存储所有Parallel Adapter的可训练权重。在训练和推理过程中,将当前上下文输入的FFNs隐藏状态作为查询 (query),与相应Parallel Adapter的键 (key) 进行相似度计算,选择相似度高的稀疏键值对集合,复制到GPU上进行训练。通过减少CPU与GPU间传输的参数量,降低了PCIe上的通信量,提高了训练效率。其次,由于相似度计算复杂度较高,在CPU上的计算压力大,本文采用了一个类似于MoE(混合专家模型)的结构,使用Router将隐藏状态路由给最有可能相似度高的键值区块(即“专家”),从而减轻CPU上的计算压力。我们在多个知识密集型任务上的实验表明,在可接受的训练效率损失条件下,该方法在资源有限的情况下对LLMs的微调效果超过了其他PEFT方法,达到了与资源消耗更大的全量微调相当的结果。
标题:MELoRA: Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning 作者:Pengjie Ren, Chengshun Shi, Shiguang Wu, Mengqi Zhang, Zhaochun Ren, Maarten de Rijke, Zhumin Chen, Jiahuan Pei 简介:大语言模型在多种任务上展现出了强大的能力,但随着模型规模越来越大,对模型进行下游任务微调所需要的资源也逐渐变多。一种新的微调方式——参数高效微调(PEFT)应运而生,参数高效微调算法通过微调模型的部分特定模块或者增加少量参数进行微调,从而大幅降低的可训练参数量,大大降低了资源需要。其中LoRA由于其简单易用并且不会增加新的推理成本得到了广泛的使用,但是LoRA使用低秩近似拟合参数修改量,对于较为复杂的任务时往往会带来较大的损失。针对LoRA存在的这一问题,我们提出了MELoRA,它使用了更少的可训练参数,同时保持了更高的秩,从而提供了更强的拟合能力。MELoRA的核心思想就是冻结原始的预训练的权值,并训练一组mini LoRAs,不同的mini LoRA学习不同维度的特征,从而提高更好的泛化能力。我们在各种自然语言处理任务进行了理论分析和实验论证。实验结果表明,与LoRA相比,MELoRA在自然语言理解任务上使用1/8的可训练参数,指令跟随任务上使用1/36的可训练参数,都实现了更高的性能。

标题:Generate-then-Ground in Retrieval-Augmented Generation for Multi-hop Question Answering 作者:Zhengliang Shi,Shuo Zhang,Weiwei Sun,Shen Gao,Pengjie Ren,Zhumin Chen,Zhaochun Ren 简介:多跳问答任务由于需要大量的知识推理,对大型语言模型 (LLM) 提出了重大挑战。 当前的解决方案,例如检索增强生成,通常从外部语料库中检索潜在文档来读取答案。然而,这种先检索再抽取的范式受到检索器的性能约束,并且会收到文档中不可避免的噪声的干扰。为了解决这些挑战,我们引入了一种新的生成-修改框架,有效地协同大规模语言模型的内部知识和外部的文档来解决多条问答任务。我们的方法引导语言模型交替以下两个阶段,直到得出最终答案:(1) 推演一个更简单的单跳问题并直接生成答案;(2) 将问答与相关的文档进行匹配,修改答案中的任何错误信息。 我们还提出了一种指令式蒸馏方法,将我们的框架推广到更小的模型中。我们在四个数据集进行的广泛实验,并验证了我们方法的优越性。

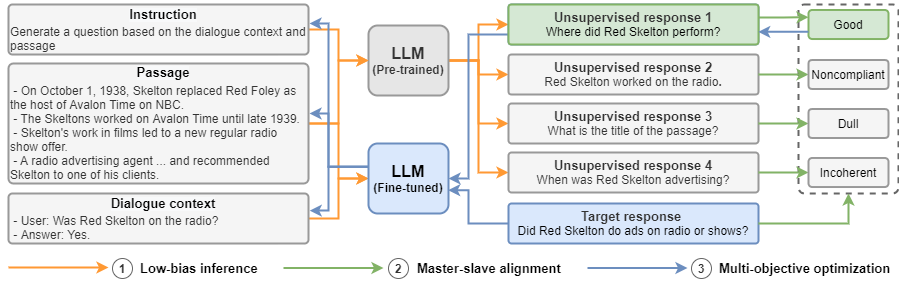
标题:Zero-Shot Position Debiasing for Large Language Models 作者:Zhongkun Liu,Zheng Chen,Mengqi Zhang,Zhaochun Ren,Zhumin Chen,Pengjie Ren 简介:微调已被证明是提高大语言模型(LLMs)领域/专业性能的有效方法。然而,LLMs可能会通过拟合数据集中的偏置(bias)或捷径(shortcuts)来进行预测,从而导致泛化性能较差。已有研究证明,LLMs容易表现出位置偏置(position bias),即倾向于利用位于模型输入开头或结尾的信息或特定位置的信息。为了去除这些偏置,已有的大语言模型去偏方法往往需要外部偏置知识或有标注的无偏样本,但这些知识对于位置去偏是缺乏的,并且这类方法在现实难以直接应用。因此,在这项工作中,我们提出了一个零样本位置去偏(ZOE)框架,以减轻LLMs的位置偏置。ZOE利用预训练大语言模型的无监督回复进行去偏,而不依赖任何外部知识。由于这些无监督回复难以适应提出的去偏目标,我们提出了一个主从目标对齐(MSA)模块来修剪这些回复。在五个任务、八个数据集上的实验表明,ZOE在减轻三种类型的位置偏置方面优于现有方法。此外,ZOE仅仅牺牲了在有偏样本上的少量性能,具有通用性和有效性。
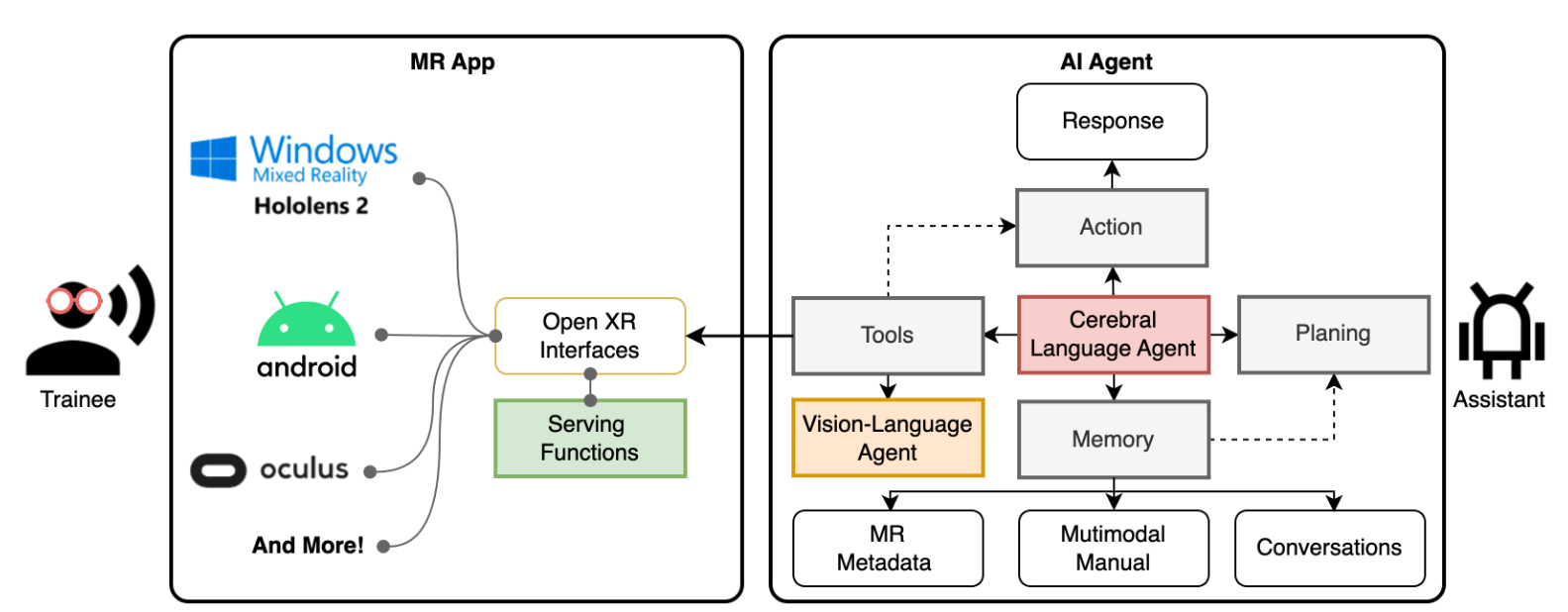
标题:Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality 作者:Jiahuan Pei, Irene Viola, Haochen Huang, Junxiao Wang, Moonisa Ahsan, Fanghua Ye, Yiming Jiang, Yao Sai, Di Wang, Zhumin Chen, Pengjie Ren, Pablo Cesar 简介:随着大型语言模型( LLMs )的逐步发展,自主人工智能Agent已经成为自动理解基于语言的环境的一种新的方式。我们提出了一种新的自主工作流程,旨在将Agent无缝集成到混合现实(MR)应用中,以实现细粒度训练。我们设计了一个用于乐高积木组装的多模态细粒度训练助手,并在MR环境中进行了演示。该工作流程的核心是一个多Agent组合,它结合了大型语言模型(LLM)与记忆、规划以及与MR工具的交互能力,以及一个视觉-语言Agent代理,使Agent能够基于以往的经验来决定其行动。此外,我们还发布了一个名为LEGO-MRTA的多模态细粒度组装对话数据集,该数据集由LLM自动合成,包括多模态指令、对话、MR响应和视觉问题回答。我们评测了多个开源LLM作为Agent的性能表现,并且工作流程具有广泛社会意义,比如提高工人培训效率和降低公司培训成本。