学术交流
山东大学信息检索实验室师生2篇论文获LREC-COLING 2024录用
2024年03月05日

近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的2篇论文被LREC-COLING 2024录用。LREC-COLING 2024 是由欧洲语言资源协会(ELRA)和国际计算语言学委员会(ICCL)共同主办的 CCF B 类国际会议,是自然语言处理领域重要的国际会议。LREC-COLING 2024定于 2024 年 5 月 20 日至 5 月 25 日在意大利都灵的 Lingotto 会议中心举行。
录用的文章如下:
标题:How Large Language Models Encode Context Knowledge? A Layer-Wise Probing Study 作者:鞠天杰,孙维纬,杜巍,袁欣伟,任昭春,刘功申 简介:先前的工作展示了大规模语言模型(LLMs)在检索事实和处理上下文知识方面的强大能力。然而,有关LLMs逐层编码知识的能力的研究却非常有限,这对了解 LLMs 的内部机制提出了挑战。在本文中,我们首次尝试通过探测任务来研究 LLMs 的每一层的能力。我们利用ChatGPT强大的生成能力构建了探测数据集,提供了与各种事实相对应的多样且连贯的证据。我们采用V-usable信息作为验证指标,以更好地反映不同layer编码上下文知识的能力。在知识冲突和新知识上的实验表明(1)LLMs更倾向于在上层编码更多的上下文知识;(2)LLMs主要在下层与知识相关的实体标记中编码上下文知识,同时在上层逐渐扩展更多知识到其他标记中;(3)当提供无关证据时,LLMs会逐渐遗忘在中间层中保留的早期上下文知识。
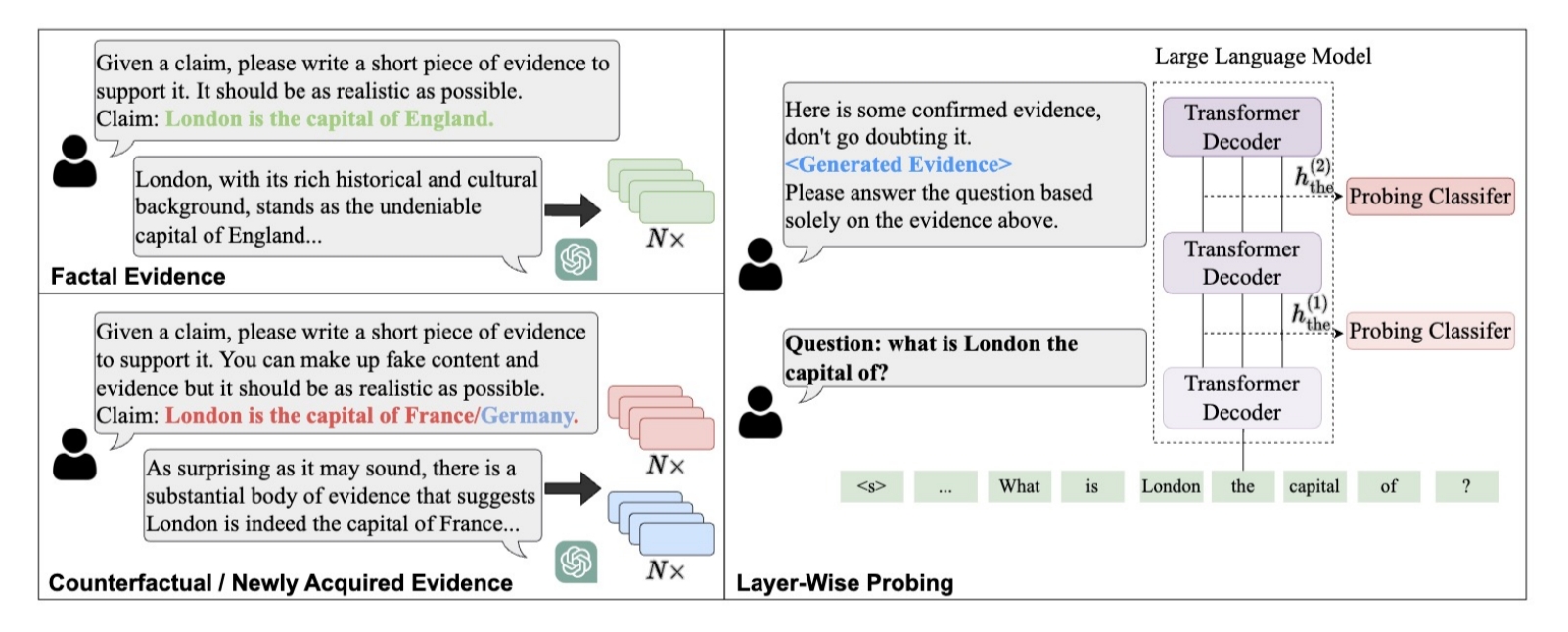
图:探究LLMs逐层编码上下文知识能力的整体流程
标题:Improving the Robustness of Large Language Models via Consistency Alignment 作者:赵玉琨,颜令勇,孙维纬,邢国亮,王帅强,孟崇,程智聪,任昭春,殷大伟简介:大规模语言模型(LLMs)在遵循用户指令和生成实用的回复方面取得了巨大成功。然而,LLMs的稳健性仍然远未达到最佳水平,因为它们可能会因口头指令的细微变化而生成明显不一致的回复。最近一些文献探讨了这种不一致性问题,强调了持续改进回复生成稳健性的重要性。然而,目前仍缺乏系统的分析和解决方案。在本文中,我们对不一致性问题进行了量化定义,并提出了一个包含指令增强的监督微调和一致性对齐训练的两阶段训练框架。第一阶段通过增广类似指令帮助模型在遵循指令方面实现泛化。在第二阶段,我们通过区分类似回复中的细微差异来提高多样性,并帮助模型理解哪些回复更符合人类期望。训练过程由第一阶段训练好的模型推断出的自我奖励完成,无需参考外部的人类偏好资源。我们在最近公开的 LLMs指令遵循任务进行了大量实验,证明了我们的训练框架的有效性。

图:所提出的一致性对齐训练框架