学术交流
山大信息检索实验室师生论文获AAAI 2023录用
2022年11月24日
近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的 2 篇论文被 AAAI 2023 录用。
AAAI 2023会议即第37届AAAI人工智能大会(The 37th AAAI Conference on Artificial Intelligence, AAAI 2023), 计划于2023年2月7日-14日于美国华盛顿举行。AAAI全称Association for the Advancement of Artificial Intelligence,是人工智能领域的主要学术组织, 汇集了全球顶尖人工智能领域专家学者,主办的AAAI会议是人工智能研究领域的旗舰会议,也是CCF推荐的人工智能方向A类会议。
录用的文章如下:
标题:Feature-Level Debiased Natural Language Understanding 作者:吕由钢,李丕绩,杨业昶,Maarten de Rijke,任鹏杰,赵玉琨,殷大伟,任昭春 内容简介:现有的自然语言理解模型通常依靠数据集偏差而不是预期的任务相关特征来实现特定数据集上的高性能。因此,这些模型在训练分布之外的数据集上表现不佳。最近的一些研究通过在训练过程中减少有偏差的样本的权重来解决上述问题。然而,这些方法仍然在表征中编码了偏差特征,并且忽略了偏差的动态性质,这阻碍了模型的预测。 我们提出了一种名为DCT的自然语言理解去偏方法来同时缓解上述问题。具体地,我们设计了一个去偏正采样策略,通过选择最不相似的偏差正样本来缓解偏差特征。此外,我们还提出了一个动态的负采样策略,通过使用偏差模型来动态地选择最相似的偏差负样本来捕捉偏差的动态影响。我们在三个自然语言理解基准数据集上进行了实验。实验结果表明,DCT在分布外数据集上的表现优于最先进的基线,同时保持了分布内性能。我们还验证了DCT可以从模型的表征中减少偏差特征。
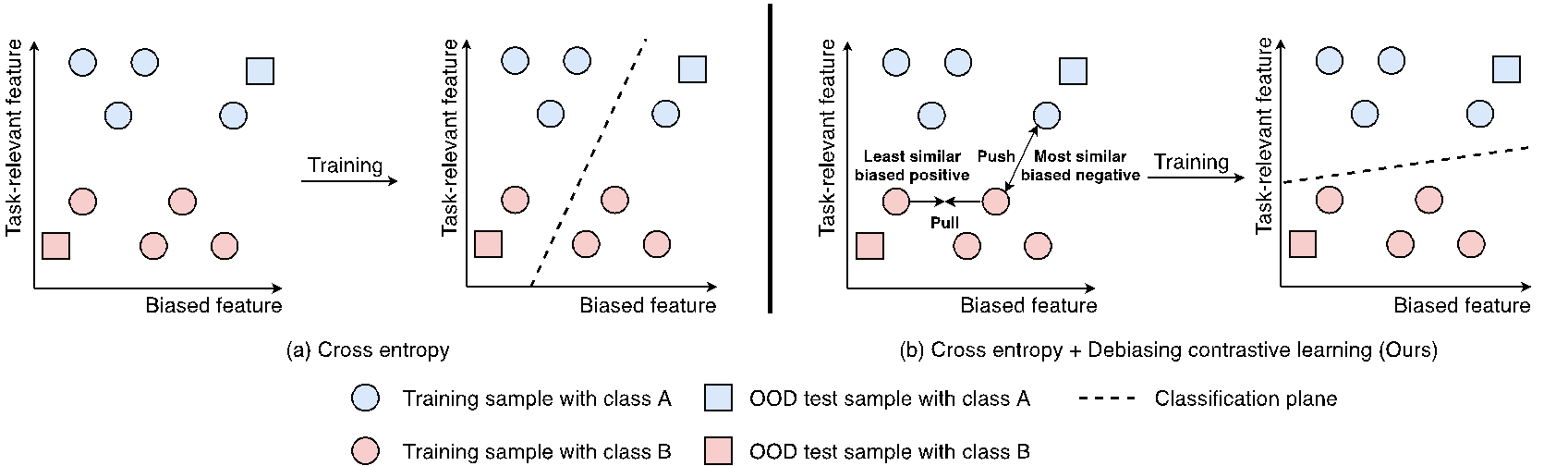
图: 本工作(b)与直接微调的区别
标题:Contrastive Learning Reduces Hallucination in Conversations 作者:孙维纬, 施政良, 高莘, 任鹏杰, Maarten de Rijke, 任昭春 内容简介:预训练语言模型将知识存储在他们的参数中,当在对话系统中使用预训练语言模型时,其可以利用储存的知识生成具有信息量的回复。但是,语言模型在生成回复时存在“幻觉“的问题,即他们会生成看似合理,但实际上和对话不相关,或事实性错误的内容。针对这个问题,我们提出了一个对比学习的方法,称为MixCL。 我们提出了一个新的对比学习训练目标,用于显式的优化语言模型激发其隐式知识的过程,并因此降低他们在对话中的幻觉问题。我们同时设计了基于检索的负样本和基于模型的负样本用于对比学习训练。我们在Wizard-of-Wikipedia,一个开放式基于知识的对话数据上进行实验,并验证MixCL的有效性。我们通过实验展示MixCL可以有效的降低预训练语言模型在对话中的幻觉。MixCL在回复相关性和事实性上取得了在已有的基于语言模型的方法中最好的效果。在和基于检索的方法对比时,MixCL取得了可比的效果并在模型高效性和规模可扩展性上具有明显的优势。
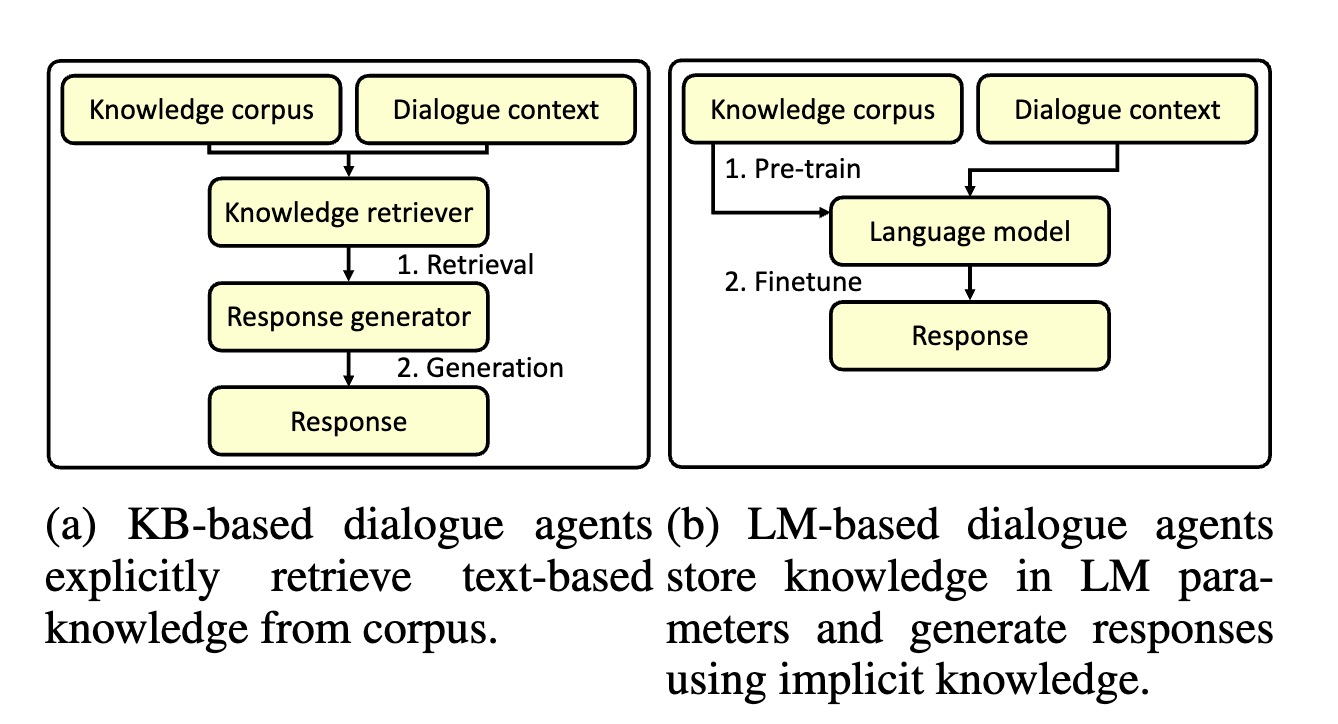
图: 两种对话模型,(a)基于知识库检索的模型,(b)基于预训练语言模型的模型。
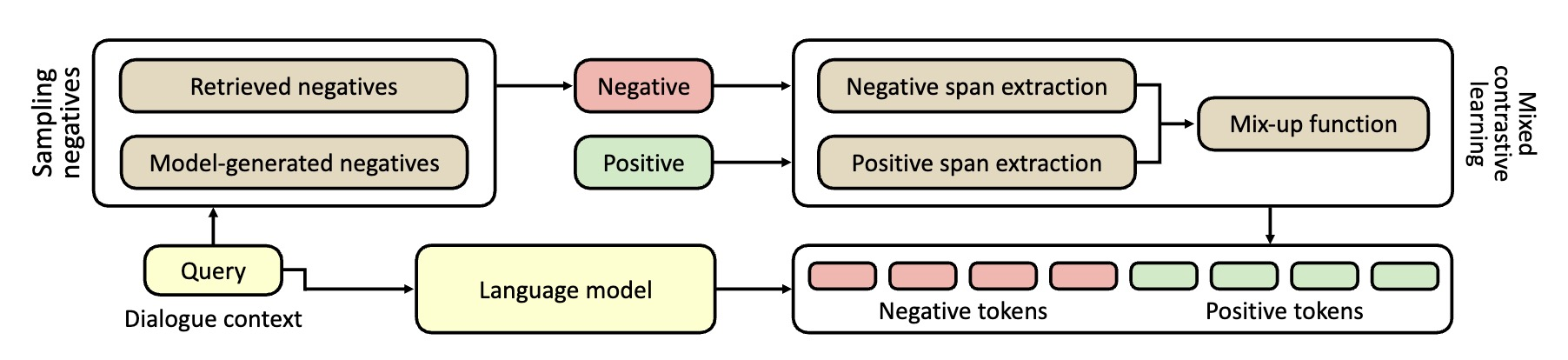
图: MixCL方法。方法包括两步:(1)负样本采样,用于采样模型容易混淆的负样本知识;(2)混合对比学习,用于降低负样本字符的生成概率,提高正确知识的生成概率。