学术交流
热烈祝贺山东大学信息检索实验室师生论文被SIGKDD2022接收
2022年5月20日
近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的 1 篇论文被 SIGKDD 2022 Research Track 录用为长文。
第 28 届国际知识发现和数据挖掘大会(The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining)将于 2022年8月14日 – 8月18日在美国华盛顿召开。SIGKDD 是中国计算机学会 CCF-A 类会议,在相关领域享有较高学术声誉。本次会议 Research Track 共收到 1695 篇长文投稿,仅有 254 篇长文被录用,录用率约 15%。
录用的文章如下:
标题:Debiasing Learning for Membership Inference Attacks Against Recommender Systems
作者:王梓涵,黄娜,孙飞,任鹏杰,陈竹敏,罗恒亮,Maarten de Rijke, 任昭春
内容简介:在从生物医学数据到移动性跟踪等领域,研究者们通过成员属性推断研究应用系统中隐含的隐私威胁,均已取得重大成功,但这些方法因为需要一些先验知识而不能直接应用于推荐系统。最近,在推荐系统领域,有研究工作根据用户的历史交互项目与推荐项目之间的相似性来推断目标系统的成员属性,但该框架存在两个挑战性问题:
第一,成员推断模型的训练数据存在偏差。由于目标推荐系统不可访问,成员推断模型构建的影子推荐系统与目标推荐系统差异较大,生成的成员推断模型的训练数据存在偏差。第二,差分向量的估计不准确。目标推荐系统的隐藏状态对成员推断模型不可见,用户的历史交互项目和推荐项目之间的差异向量不能被准确估计,产生不正确的成员属性推断。
本文针对以上两个挑战性问题,提出了一种针对推荐系统成员推断攻击的去偏学习方法。如图1所示,该框架由差分向量生成器、解耦编码器、权重估计器,以及成员推断模型组成。为了模拟目标模型的行为,首先在影子数据集上构建和学习影子推荐系统,然后利用差分向量生成器分解用户-项目评分矩阵生成用户的历史交互项目和推荐项目的表示并计算差异向量。为了减轻由目标推荐系统和影子推荐系统之间的差异导致的训练数据偏差,我们采用基于两个分布族的变分自动解耦编码器识别不变性和特定性特征。为了减少估计偏差的影响,我们建立一个权重估计器,为每个差异向量分配一个表征其真实水平的分数。最后,将解耦并重新赋权的差异向量以及成员标签输入基于多层感知器的成员推断模型中。
通过实验,我们发现该去偏学习方法能够显著地缓解针对推荐系统的成员推断攻击中存在的偏差问题,实现更准确的成员属性推断,为推荐系统中的隐私风险提供更准确的评估量化。
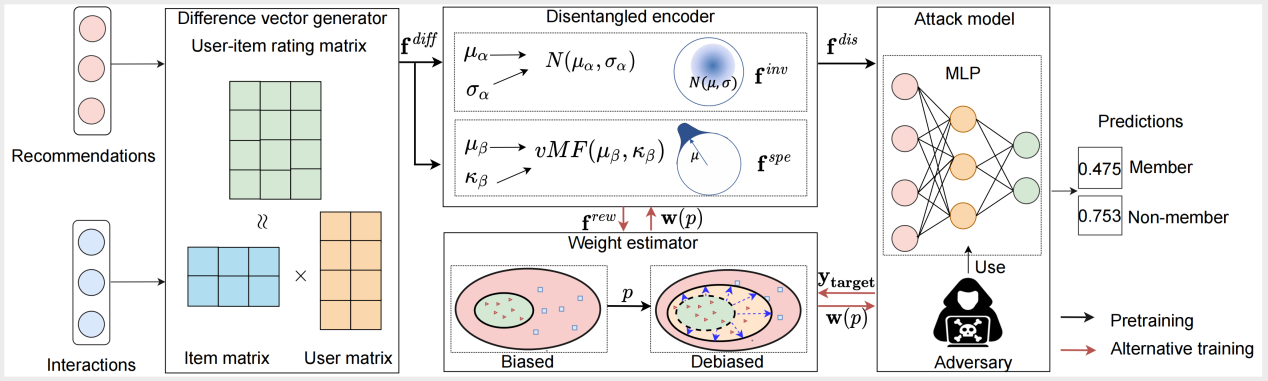
图: 针对推荐系统成员推断攻击的去偏学习模型图