学术交流
夫子•明察司法大模型在大语言模型司法能力评估中表现卓越
2023年11月5日
近日,南京大学和上海人工智能实验室合作构建了LawBench的数据集,旨在对中文法律问答模型进行全面深入的评估。所评估的模型范围涵盖了51种热门的大型语言模型,包括LLaMA系列、Qwen系列等。这些模型可以分为通用多语言模型、中文优化模型,以及在法律文本上进行过训练的法律专精模型三类。在法律专精的模型中,由山东大学、浪潮云、中国政法大学联合研发的司法领域大模型——夫子•明察司法大模型表现出色,取得了最佳成绩。
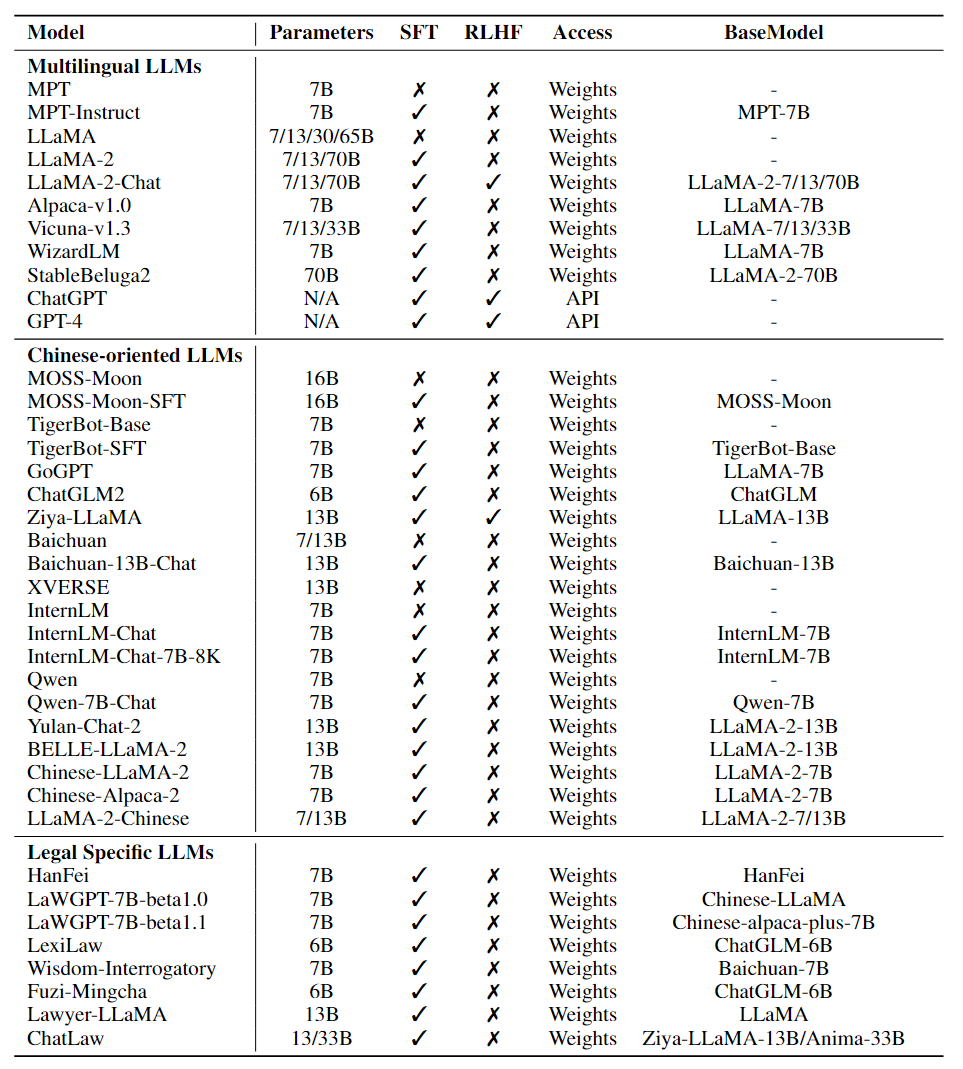
图1 评估模型列表
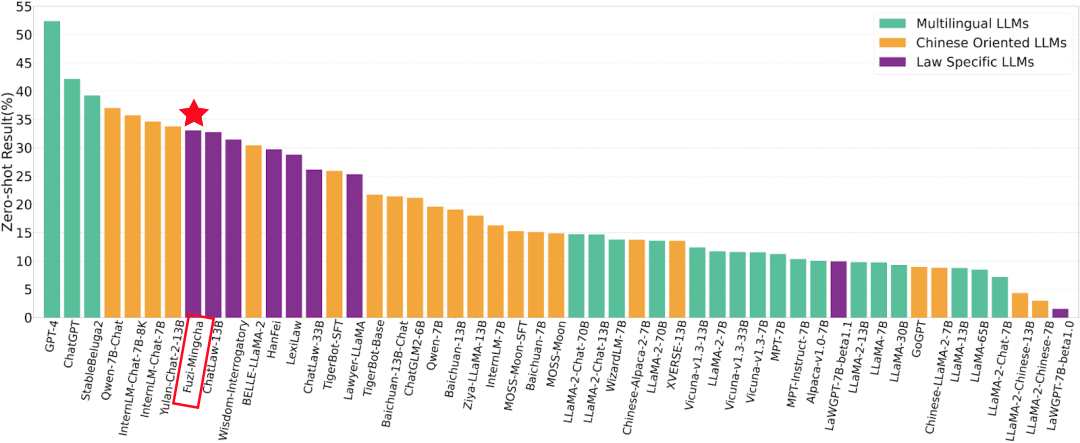
图2 夫子•明察司法大模型在法律专精的模型中表现位列第一
夫子•明察司法大模型是由山东大学、浪潮云、中国政法大学联合研发,基于海量中文无监督司法语料(包括各类判决文书、法律法规等)与有监督司法微调数据(包括法律问答、类案检索)训练的中文司法大模型。该模型支持法条检索、案例分析、三段论推理判决以及司法对话等功能,旨在为用户提供全方位、高精准的法律咨询与解答服务。
项目地址:https://github.com/irlab-sdu/fuzi.mingcha
内测申请:https://docs.qq.com/form/page/DVkdpdWFkbGNBWklk
文中图1图2以及模型评估结果均来自公众号OpenMMLab,详情请访问:
上海AI实验室联合南京大学推出大语言模型司法能力评估体系