学术交流
山大信息检索实验室师生5篇论文获ACL2023录用
2023年5月6日

近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的5篇长文被ACL 2023录用。其中3篇被ACL主会录用,2篇被录用为Findings。ACL2023(The 61st Annual Meeting of the Association for Computational Linguistics)计划于今年7月9日至14日在加拿大多伦多召开。ACL是人工智能领域自然语言处理(Natural Language Processing,NLP)方向最权威的国际会议之一,也是CCF A类会议。录用的文章列表如下:
Main Conference:
标题:Answering Ambiguous Questions via Iterative Prompting 作者:孙维纬,蔡恒毅(京东),陈宏申(京东),任鹏杰,陈竹敏,Maarten de Rijke (阿姆斯特丹大学),任昭春 简介:在开放式问答中,用户提出的问题常常是模糊的,带有歧义的,这些问题可能有多个可行的答案。为了回答这类问题,通常有两种方式。一种是直接预测所有可能的答案,但是这种方法难以平衡答案集合的相关性和多样性。另一种方式是收集多个候选答案并聚合,但这种方式通常计算开销高,且往往忽视了答案之间的关联性。为了解决这些难题,本文提出了AmbigPrompt。具体来说,我们采用了一种迭代式的方法,将一个提示模型整合到问答模型中。提示模型通过适应性的追踪问答模型的阅读过程,渐进式的指导问答模型生成新的答案,从而提高了答案的质量和相关性。此外,我们还设计了任务特定的后预训练方法,利用构造的数据对问答模型和提示模型进行预训练。我们在两个常用的基准数据集上进行了实验,结果表明AmbigPrompt在答案准确性和多样性上取得了很好的结果,而且所需的存储和计算开销更少。此外,AmbigPrompt在低资源设定下也表现很好。
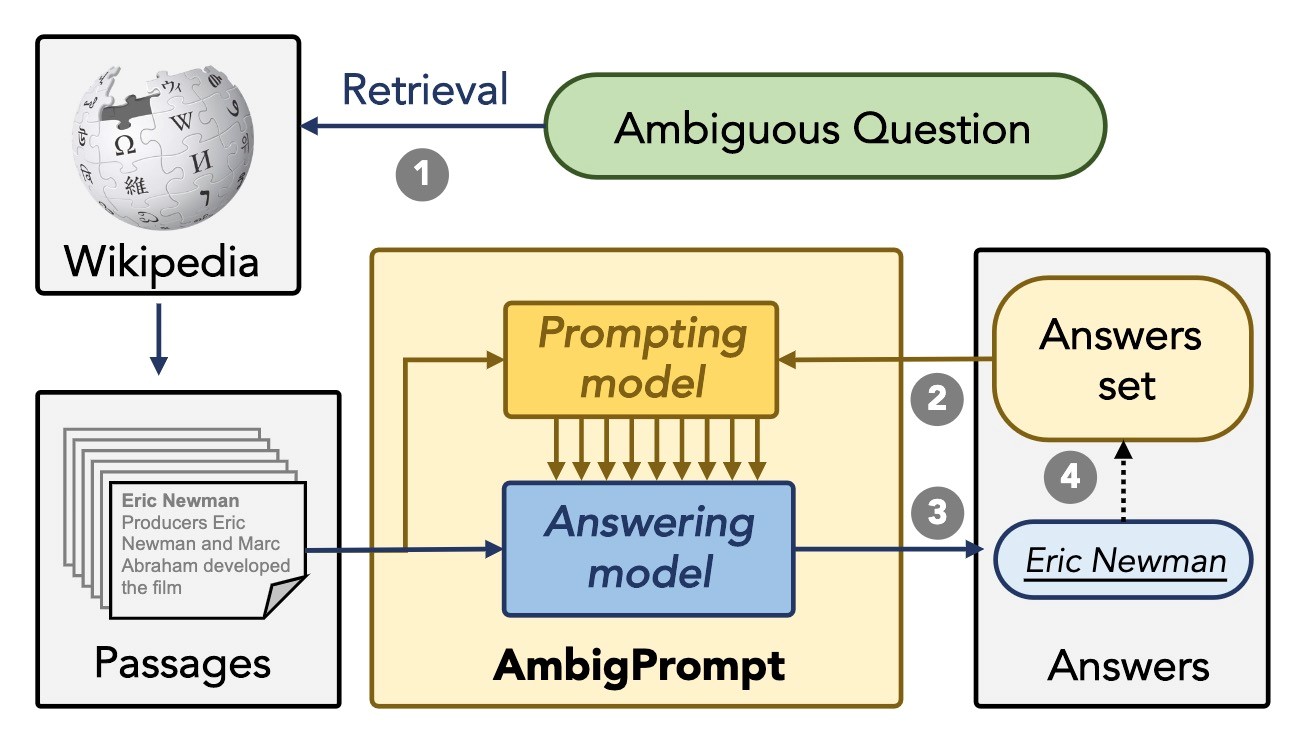
图:AmbigPrompt方法示意图
标题:RADE: Reference-Assisted Dialogue Evaluation for Open-Domain Dialogue 作者:施政良,孙维纬,张硕(Bloomberg),张振,任鹏杰,任昭春简介: 开放域对话系统专注于非任务型导向的聊天,可以针对任意主题进行对话。在开放域对话系统中,给定一个上文,合适的回复并不唯一。如何有效缓解这种一对多问题,实现有效的自动评估仍是一个亟待解决的问题。现有的自动评估方法大致可以分为reference-based和reference-free两类。前者将数据集中标注好的标签视为唯一的正确答案,忽视了对话开放性的特点;而后者基于对话上文和系统输出之间的关联关系进行建模,一定程度上解决了一对多问题,但仍存在由数据以及模型结构引入的偏差。 基于上述分析,我们结合多任务学习的思路,提出了reference-assisted评估方法(RADE)。一方面,该方法在评估系统输出的基础上,同时对数据集中的标签进行评估,并设计了成对对比的损失函数进行监督。另一方面,该方法引入了额外的生成式任务作为辅助,将利用共享参数的编码器感知候选的语义空间,从而在一定程度上缓解了开放域对话的一对多问题。为了支持模型的训练,我们扩展了三个现有的数据集(PersonaChat, DSTC以及Empathetic Dialogue),并采用两阶段的训练方式,兼顾模型在领域内场景下评估的性能以及领域外场景下的泛化性。为了验证方法的有效性,我们选了五个数据集进行测试,包括三个新标注的数据集和两个现有的数据集(USR-Topical和USR-Pearsona)。实现结果表明,我们的模型与人工评估具有较高的一致性,且具有较好的泛化能力。
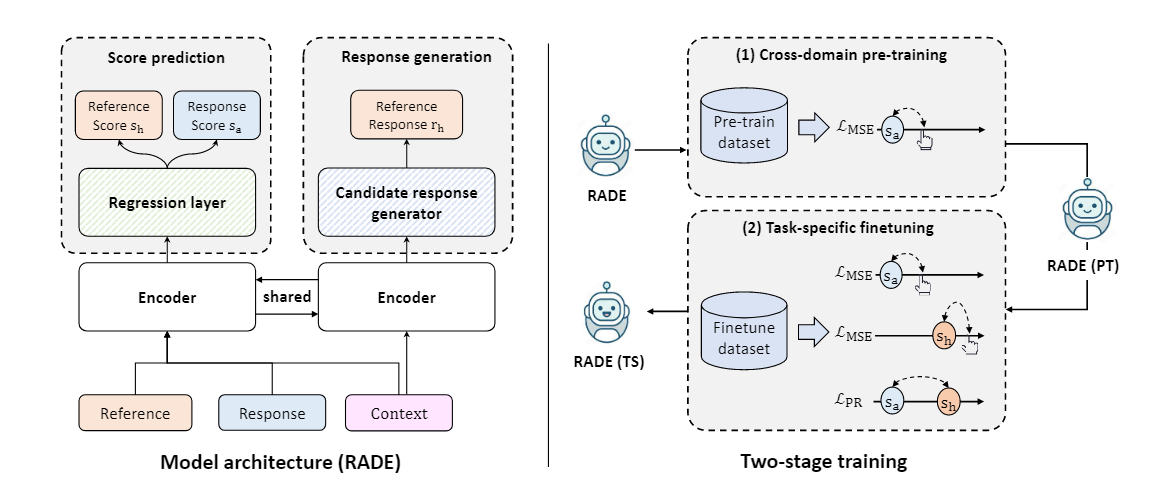
图:左图为RADE模型结构,右图为两阶段训练方式
标题:Dialogue Summarization with Structure-aware Graph Modeling via Static-Dynamic Fused Graph 作者:高莘,程信(北京大学),李明哲(蚂蚁集团),陈秀颖(阿卜杜拉国王科技大学),李金鹏(北京大学),赵东岩(北京大学),严睿(中国人民大学)简介: 对话是语言中最基本与特殊的领域,在近年来的互联网中随处可见。在许多实际的Web应用程序中,快速浏览长对话并捕捉遍布于整个对话中的重要信息都有应用,例如电子邮件摘要和会议记录。对话摘要是一个具有挑战性的任务,因为对话具有动态交互性质,各个发言人之间的信息流也可能不一致。许多研究人员通过使用外部语言工具包将对话建模为预先计算好的静态图结构来解决这个任务。然而,这些方法严重依赖于外部工具的可靠性,而静态图结构的构建与图表示学习阶段不一致,使得图不能动态地适应下游摘要任务。本文提出了一种基于静态-动态图的对话摘要模型(SDDS),它融合了人类专业的先验知识,并以端到端的学习方式自适应地学习图结构。为验证SDDS的有效性,我们在三个基准数据集(SAMSum、MediaSum和DialogSum)上进行了实验,结果验证了SDDS的优越性。
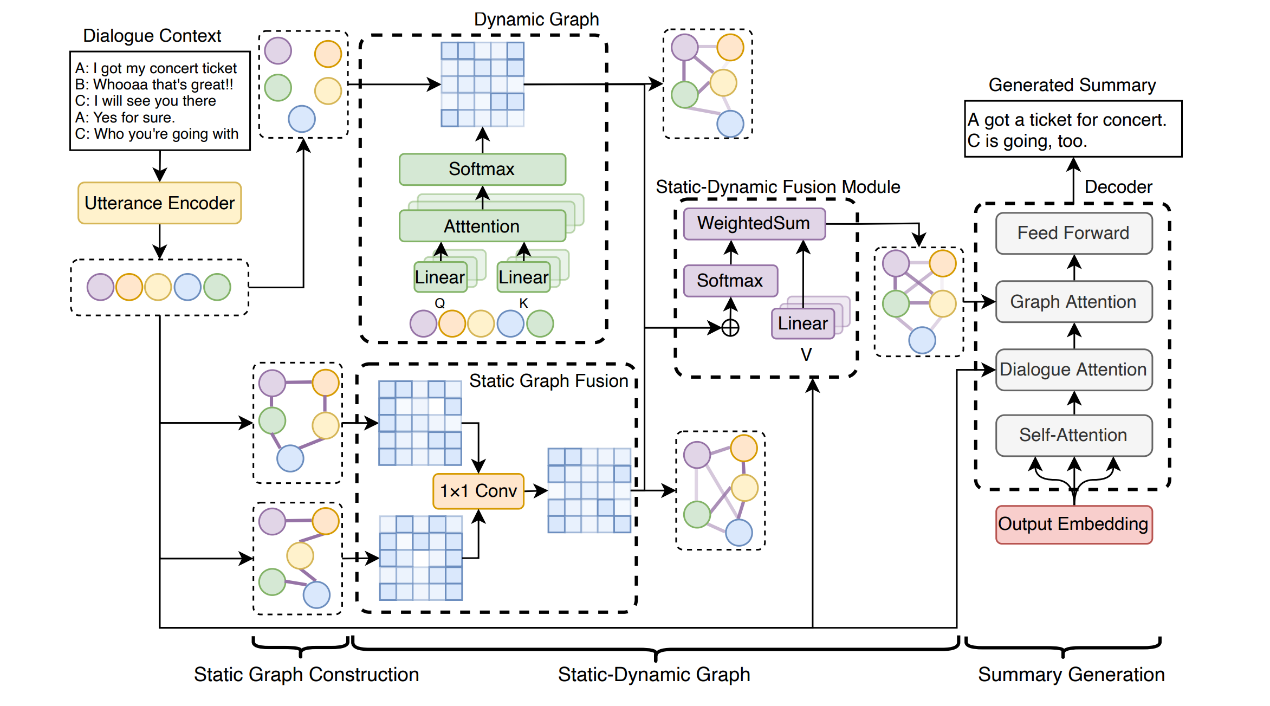
图:基于静态-动态图的对话摘要模型示意图
Findings:
标题:UMSE: Unified Multi-scenario Summarization Evaluation 作者:高莘,姚智涛,陶重阳(微软),陈秀颖(阿卜杜拉国王科技大学),任鹏杰,任昭春,陈竹敏 简介:摘要质量评估是文本摘要中一个非常重要的任务。现有方法主要分为两种场景:(1)基于参考的场景,即使用人工标注的参考摘要来进行评估;(2)无参考的场景,即评估摘要与文档的一致性。最近的研究主要聚焦于单一场景,并探索使用预训练语言模型构建评估模型,以符合人类的标准。然而,不同场景下的模型被单独优化,忽略了不同场景之间的知识共享,可能导致次优性能。此外,为每种场景设计单独的模型会给用户带来不便。因此,我们提出了统一的多场景摘要评价模型(UMSE)。具体地,我们提出了扰动前缀微调方法,以在不同场景之间共享跨场景知识,并使用自监督训练范式来优化模型,无需额外的人工标注。UMSE是第一个可以用于三种评估场景的统一摘要评估框架。在SummEval基准数据集的三个场景下进行的实验结果表明,UMSE可以达到与现有的针对每种场景特别设计的方法相当的性能。
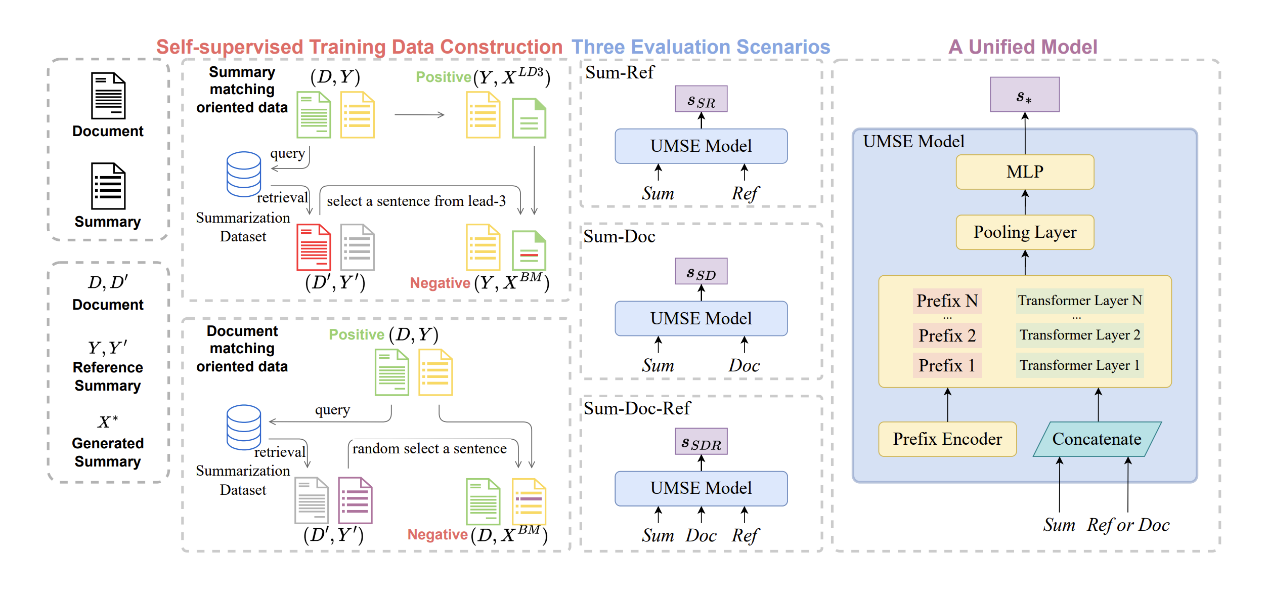
图: 统一的多场景摘要评价模型示意图
标题:SSP: Self-Supervised Post-training for Conversational Search 作者:涂权(中国人民大学),高莘,吴小龙(华为),曹朝(华为),文继荣(中国人民大学),严睿(中国人民大学) 简介:对话式搜索现已被视为下一代搜索范式。受数据稀缺性的限制,大多数现有方法使用训练好的的即席检索器来训练对话式检索器。然而,这些通过重构查询来初始化对话式检索器参数的方法在理解对话结构信息和解决上下文语义消失问题上存在困难。在本文中,我们提出了一种新的具有多个自监督任务后训练范式SSP,可以有效地初始化对话式检索模型,以增强对话结构和上下文语义理解。此外,SSP 可以插入大多数现有的对话式检索模型以提高它们的性能。为了验证我们提出的方法的有效性,我们在CAsT-19 和 CAsT-20两个基准数据集对SSP后训练的对话式检索器进行实验。实验表明SSP 可以提高多种现有对话式搜索方法的性能。
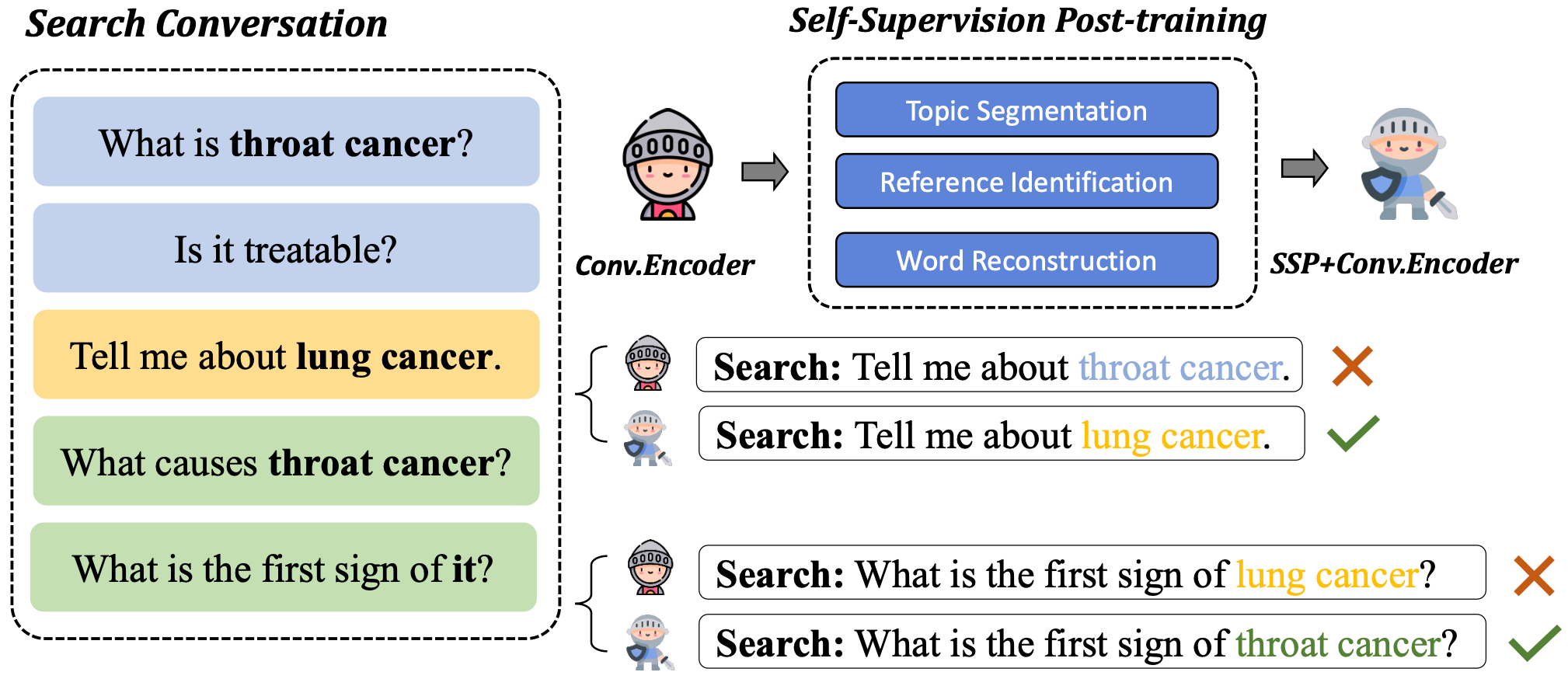
图: 基于自监督后训练的对话检索模型示意图