学术交流
热烈祝贺山东大学信息检索实验室师生论文被SIGIR2022接收
2022年4月7日
近日,山东大学计算机科学与技术学院信息检索实验室师生撰写的5篇论文被SIGIR 2022录用。3篇为full paper,1篇为resource paper,1篇为short paper。
第45届国际信息检索大会(The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval)将于2022年7月11日-7月15日在西班牙马德里召开。SIGIR是是信息检索领域的旗舰会议,也是中国计算机学会CCF推荐的A类会议。
Full Paper:
标题:Rethinking Reinforcement Learning for Recommendation: A Prompt Perspective 作者:辛鑫, Tiago Pimentel(剑桥大学), Alexandros Karatzoglou(谷歌), 任鹏杰, Konstantina Christakopoulou(谷歌), 任昭春 简介:现代推荐系统旨在提升用户体验;因为强化学习(RL)自然符合推荐系统的优化目标—最大化一个交互会话中的总体收益—因此在推荐系统中探索RL的使用是一个新兴的研究点。然而,基于RL的推荐方法面临离线训练的挑战。具体来讲,传统RL算法的关键是通过大量线上试错经验进行学习,然而在推荐系统中,我们并不能让系统进行大量试错。因此,推荐引擎需要通过历史的离线数据训练。在这种离线训练的场景下,传统的RL算法会导致次优解。在本工作中,我们提出了一种新的学习范式:Prompt-basedRL(PRL)来进行离线强化学习推荐引擎的训练。传统的RL算法试图将state-action的输入映射为Q-value,而PRL则旨在从state-reward的输入中直接推断出action(被推荐物品)。简单来说,推荐引擎被用来在给定以前交互序列以及期望的奖励的情况下去预测下一个要推荐的物品。在部署的时候,历史训练数据可以被看成一个知识库,而state-reward的输入则可以被看成一个prompt。推荐引擎被用来回答以下的问题:在给定历史交互以及prompted奖励收益的情况下,哪一个物品应该被推荐。我们用了四种推荐模型(GRU,Caser,NextitNet,andSASRec)来实例化PRL,并在两个电商数据集上进行了实验,实验表明了我们提出方法的有效性。
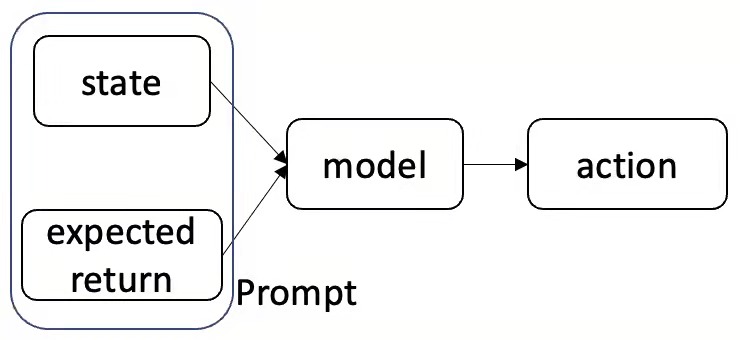
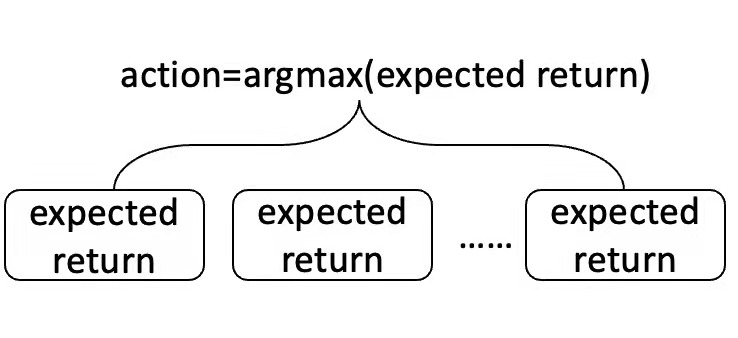
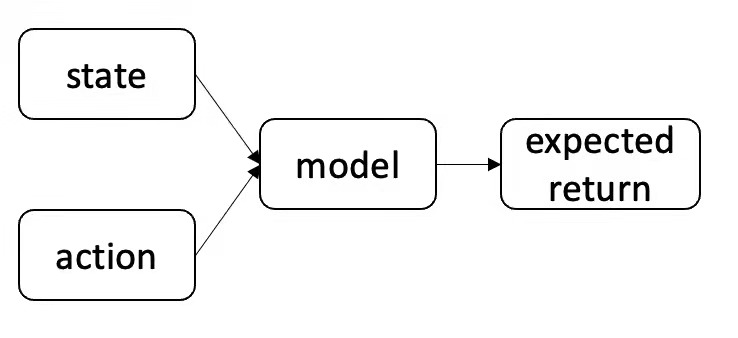
图:从左到右依次为:policy evaluation,policy improvement,PRL
标题:Variational Reasoning about User Preferences for Conversational Recommendation 作者:任昭春,田智,李冬冬,任鹏杰,杨柳,辛鑫,梁华盛(腾讯),Maarten de Rijke( 阿姆斯特丹大学 ),陈竹敏简介: 对话式推荐系统通过与用户交互来向用户提供推荐。其中一类使用模板句向用户提问并根据用户肯定或否定的回答来获取显式的用户偏好;另一类通过追踪对话主题使用自然语言与用户沟通,然而,仅仅追踪对话主题不足以真正的表示用户偏好。在本篇论文中,我们主要解决如何在对话过程中挖掘用户偏好,在这个过程中,主要有以下三个挑战:(1)一段对话往往只能反映出用户短期偏好。(2)用户的偏好是无标注的。(3)要推荐的物品和主题之间存在着复杂的语义关联。为了解决上述问题,我们提出了一种端到端的变分推理模型,具体来讲,我们将用户长期偏好和用户短期偏好建模为两个相互独立的隐变量,这两个隐变量都是关于对话主题的概率分布,我们使用随机梯度变分贝叶斯来优化变分推断所得的下界,根据用户偏好,我们使用一个策略网络来预测本轮要谈论的话题或要推荐的物品,另外,我们还使用异构知识图谱来提升推荐的效果。我们在两个基准数据集上验证了我们的模型,实验结果表明,我们在两个数据集上都超过了前人的研究。

图:一个从TG-Redial数据集上随机抽取的实例
标题:Personalized Abstractive Opinion Tagging 作者:赵梦雪,杨扬(美团),李淼(墨尔本大学),王金刚(美团),武威(美团),任鹏杰,Maarten de Rijke(阿姆斯特丹大学),任昭春 简介: 观点标签是一组总结用户对产品感受的短文本序列,通常由针对产品特定方面的一组短句组成。相较于推荐语、方面标签、产品关键词等自然语言文本,观点标签兼顾了信息的完整性和关键信息的顺序性问题,但现有观点标签的标签顺序只能反应大众化偏好,而忽略了个性化特征。本文提出了一种个性化的观点标签生成框架POT,基于产品评论提取产品关键信息,并通过用户评论和用户行为追踪用户的显式和隐式偏好,以确定关键信息的顺序,从而保证产品信息依据用户的感兴趣程度排列。我们设计了一个基于评论的层次异构图联合建模了用户、产品、方面标签和评论中的词,通过节点间深层次的信息交互,挖掘用户和产品之间的潜在关系,缓解了评论的稀疏性问题。同时,我们基于用户对产品的点击、收藏和购买行为构建了多类行为图,通过探索用户之间的相似关系进一步增强用户偏好表示。我们针对评论数据和行为数据的不同特点设计了不同的去噪模块以保证用户偏好表示的准确性。我们构建并公布了基于大众点评业务数据的个性化观点标签数据集PATag,并在生成指标和排序指标中取得了良好的效果。
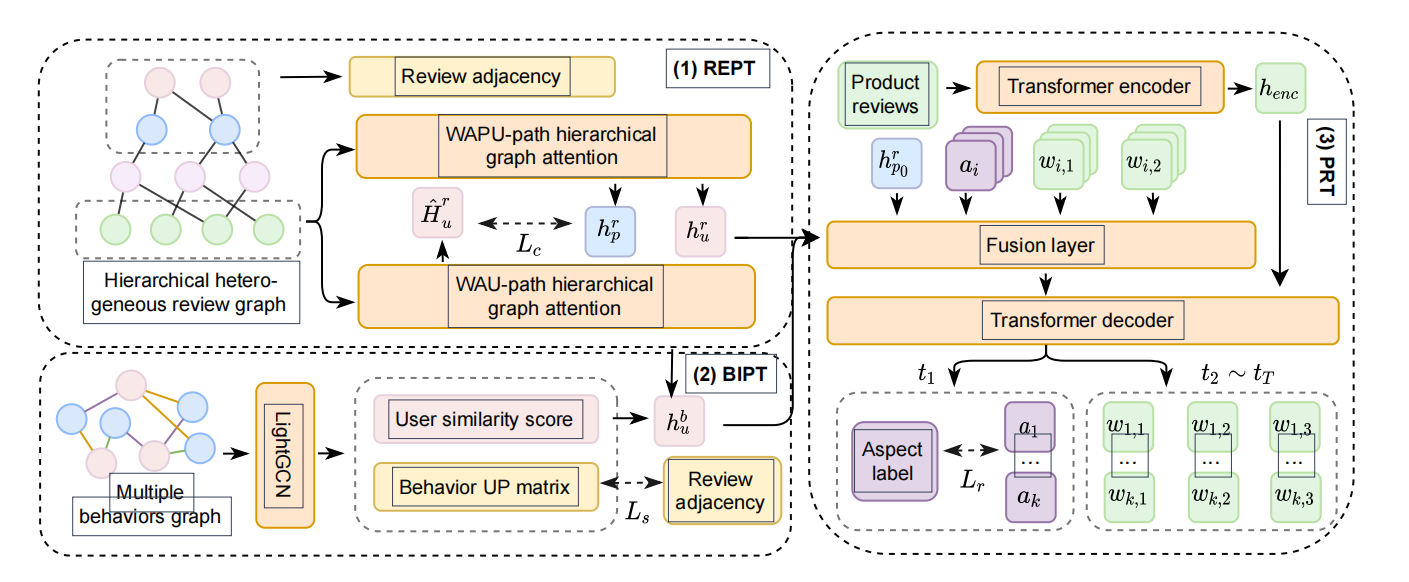
图:POT整体框架示意图
Resource Paper:
标题:ReMeDi: Resources for Multi-domain, Multi-service, Medical Dialogues 作者:严国俊, 裴家欢, 任鹏杰, 任昭春, 辛鑫, 梁华盛(腾讯),Maarten de Rijke(阿姆斯特丹大学),陈竹敏 简介:医疗对话系统可以用来辅助医生和病人完成一定范围内的专业医疗服务。例如诊断,治疗和咨询。目前医疗对话系统发展受到的主要阻碍是缺少医疗对话的资源。特别是大规模包含多种医疗服务和细粒度标签的对话数据以及建立于上的基准模型实验。在这个工作中,我们提供了ReMeDi资源,包含了医疗对话数据集和基准模型实验。数据集共包含了96965个医生和病人间的对话,其中包含了1557个人工标注的细粒度的标签的对话。此数据集包含了843种疾病,5228种医疗实体,三种医疗服务并覆盖了40种科室。基准模型实验包含了一些比较新的预训练模型,例如BERT-WWM,BERT-MED, GPT2以及MT5,除此之我们还提供了一种自监督对比学习的方法来进一步扩展我们的数据来增强我们实验的效果。

图: 一个包含诊断,治疗,咨询三种服务的实际医疗对话。右上角的知识三元组可以更容易的推断出相关
的疾病,左上角的NLU和右下角的DPL都是我们标注的具体内容,分为意图/动作-槽种类-槽值三部分。
Short Paper:
标题:Improving Conversational Recommender Systems via Transformer-based Sequential Modelling 作者:邹杰 (南洋理工大学), Evangelos Kanoulas(阿姆斯特丹大学), 任鹏杰, 任昭春, 孙爱欣(南洋理工大学), 龙程(南洋理工大学) 简介:在会话推荐系统(CRS)中,会话通常涉及一组相关的项(items)和实体(entities),例如项的属性。这些项和实体是在对话中按顺序提到的。换句话说,对话中存在潜在的顺序依赖关系。然而,大多数现有的CRS忽略了这些潜在的顺序依赖关系。在本文中,我们提出了一种基于Transformer的顺序会话推荐方法TSCR,该方法对会话中的顺序依赖关系进行建模,以改进CRS。我们通过项目和实体来表示对话,并通过考虑提到的项目和实体来构造用户序列来发现用户偏好。基于构建的序列,我们部署完形填空任务来预测序列中的推荐项。实验结果表明,我们的TSCR模型显著优于最先进的baselines。